Visual Studio Code und die Python-Konsole
Overview
Teaching: 30 min
Exercises: 0 minQuestions
Was ist eine IDE?
Wie kann man Python Code ausführen?
Objectives
Starten von VS Code und Öffnen eines Projektordners
Umgang mit der Python-Konsole
Visual Studio Code starten
Eine “Integrated Development Environment” (IDE) wie VS Code ist im Grunde ein Texteditor mit vielen Extra-Funktionen, die die Arbeit mit Quelltexten einfacher macht.
Ein Python-Programm wird am Anfang typischerweise nur aus einer einzelnen Quelltext-Datei bestehen, aber mit zunehmender Komplexität wird die Funktionalität auf mehrere Quelltext-Dateien verteilt werden.
Auch macht es für den Kurs Sinn, die Quelltexte gemeinsam in Ordnern abzuspeichern.
Legen Sie z.B. in ihrem Benutzerordner einen Unterordner lehre und darunter einen Unterordner nlp an.
Sie können den Ort des Projektordners frei wählen und je nach Betriebssystem befindet sich der Benutzerordner an anderer Stelle.
Starten Sie Visual Studio Code wie in den Setup-Schritten beschrieben. Danach sollten Sie neben dem Willkommensdialog im Zentrum auch links eine Seitenleiste sehen können.

In der Seitenleiste gibt es verschiedene Unterbereiche, zwischen denen Sie mit einem Klick auf das jeweilige Icon wechseln können. Als erstes sollten Sie den “Explorer” Unterbereich öffnen, in dem Sie auf das erste Icon oben links klicken. Öffnen sie danach den neu erstellen Projektordner in VS Code, in dem Sie in der Explorer-Seitenleiste “Open Folder” auswählen.
Alternativ können Sie einen Projektordner auch über den Menüeintrag “File -> Open Folder …” öffnen.
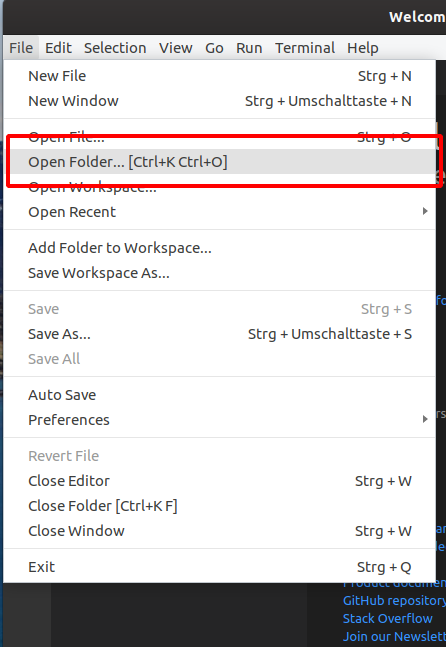
Im Moment ist der Ordner leer, deswegen werden auch im Explorer keine Dateien angezeigt. Wenn Sie die Maus auf den Bereich mit dem Ordnernamen bewegen, erscheinen zwei kleine Icons mit denen Sie entweder eine neue Datei anlegen (erstes Icon) oder einen Unterordner erstellen können (zweites Icon).

Erstellen Sie eine Textdatei mit dem Namen Notizen.txt, in dem Sie auf das Symbol für die neue Datei klicken, den Dateinamen eingeben und ⏎ (die Eingabetaste oder auch “Enter”) drücken.
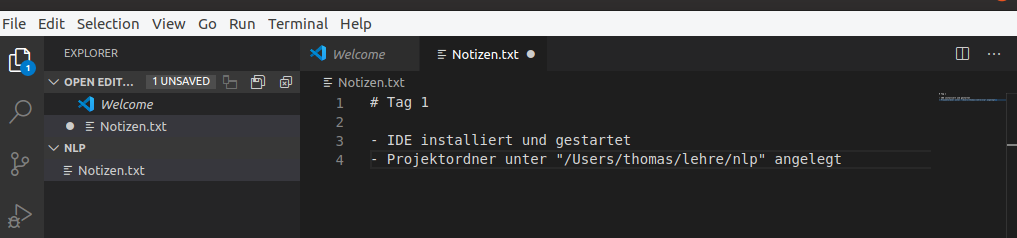
In diese Textdatei können Sie jetzt einen beliebigen Text schreiben.
Wie bei anderen Texteditoren auch zeigt VS Code an, dass die Datei geändert wurde.
Wenn es ungespeicherte Änderungen gibt, wird oben neben dem Dateinamen ein runder Kreis eingeblendet.
Speichern Sie die Änderungen mit dem Tastaturkürzel STRG+S oder den Menüeintrag “File -> Save”.
Danach wird er Kreis zu einem Kreuz, mit dem sie das Texteditorfenster schließen können.
Mit einem Klick auf den auf die Datei im der Explorer-Seitenleiste können Sie die Datei wieder öffnen.
Wenn Sie den Projektordner im Dateimanager Ihres Systems öffnen, sollten Sie die neue Datei Notizen.txt sehen können.
Python-Konsole
Bisher haben wir noch nichts mit VS Code gemacht, das spezifisch für Python wäre.
Python-Programme werden über das Programm python3 ausgeführt, das durch Miniconda mit installiert wurde.
Um das python3 Programm zu starten, müssen Sie erste einmal ein Terminal öffnen.
Sie könnten das System-Terminal starten, aber VS Code integriert bereits ein Terminal.
Um ein neues Terminal in VS Code zu starten, klicken Sie in Menü auf “Terminal -> New Terminal”.
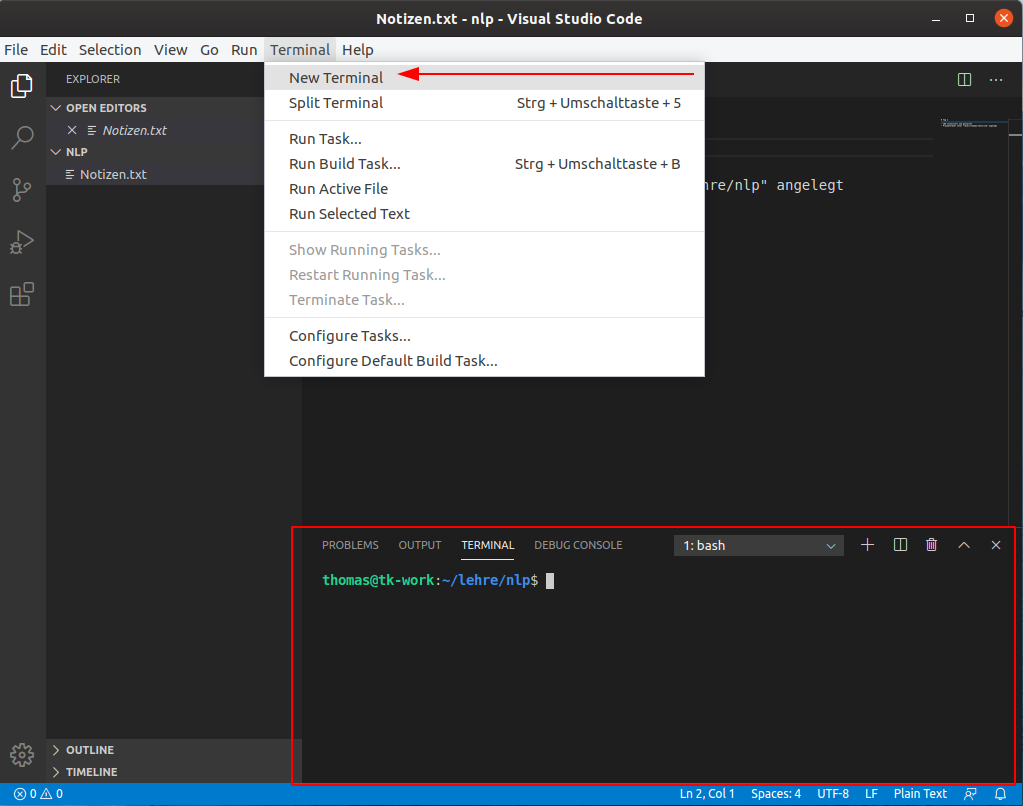
Daraufhin wird das Terminal im unteren Bereich angezeigt. Je nach Betriebsystem sieht das Terminal etwas anders aus, in MacOS und Linux wird eine Unix-Shell verwendet (z.B. “bash” oder “sh”). Wenn Sie den Befehl erneuert auswählen, wird ein neues Terminal gestartet, das alte ist dann aber immer noch da. Sie können über die “Dropdown” Box zwischen den verschiedenen Terminals hin und herschalten.
Falls Sie das Terminal verdeckt haben, können Sie diese Ansicht auch über den Menüeintrag “View -> Terminal” wieder anzeigen.
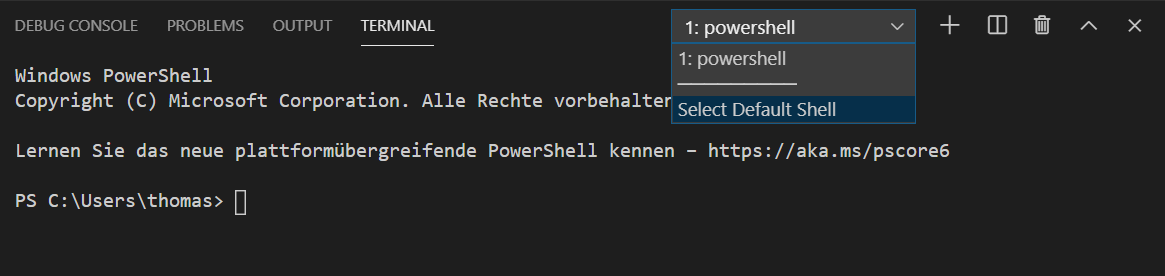
Windows Terminal-Auswahl
Windows hat die “Command Prompt” oder “Powershell” zur Auswahl. Es kann passieren, dass VS Code die Powershell startet. Für diesen Kurs ist die “Command Prompt” allerdings besser geeignet. In der gleichen Auswahl, in der Sie zwischen den offenen Terminals wechseln können, gibt es auch einen Eintrag “Select Default Shell”. Wählen Sie diesen Eintrag und klicken Sie in der darauf folgenden Auswahl auf “Command Prompt”.

Python ist auch nur ein Programm, dass über einen Terminal-Befehl gestartet werden kann. Damit die richtige Version von Python gefunden wird, müssen Sie zuerst die Miniconda-Umgebung aktivieren. Führen Sie dazu den folgenden Befehl aus:
conda activate
Nach Ausführen des Befehls wird am Anfang des Command-Prompt (base) stehen.
Danach können Sie das Programm “python3” ausführen, um die interaktive Python-Konsole zu starten:
python3
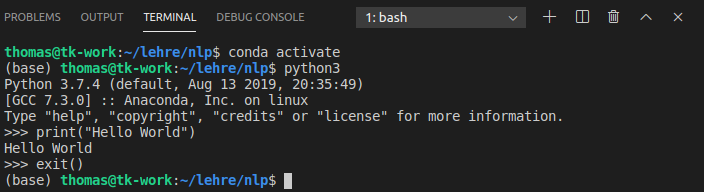
In der Python-Konsole können einzelne Python-Befehle ausgeführt und getestet werden. Z.B. können Sie die folgende Zeichenketten in die Konsole eintipppen und die Eingabetaste drücken
print("Hello World")
Jeder einzelne Befehl, der mit der Eingabetaste abgeschlossen wird kann eine Ausgabe als Text produzieren, der in der Konsole angezeigt wird sobald der Befehl abgeschlossen ist. Hier z.B. ist die Ausgabe.
Hello World
Übung
Geben Sie einen Befehl ein, der die Zeichenkette
Hallo Pythonin der Konsole anzeigt.Lösung
print("Hallo Python")
Um die Python-Konsole wieder zu beenden, geben Sie den Befehl
exit()
ein. Daraufhin sind Sie wieder im normalen System-Terminal.
Wenn Sie jetzt wieder python3 ausführen wollen, müssen sich nicht noch einmal die Conda-Umgebung aktivieren, da der Prompt (base) anzeigt, dass Conda immer noch aktiv ist.
Falls Sie VS Code oder das Terminal beenden, müssen Sie die Conda-Umgebung eventuell neu aktivieren. Je nachdem wie Sie Miniconda installiert haben, kann es auch sein, das die Conda-Umgebung bereits aktiviert ist, wenn Sie ein beliebiges Terminal starten.
Quelltext-Dateien
Python-Programme besteht aber typischerweise aus vielen Anweisungen, die in einer oder mehreren Quelltext-Datei gebündelt werden. Ein typischer Arbeitsablauf kann also sein, in der Konsole eine Abfolgen von Befehlen auszuprobieren und diese dann in die Quelltext-Datei zu kopieren.
Erstellen Sie eine neue Datei mit dem Namen hello.py und öffnen Sie diese im Texteditor von VS Code.
Die Dateiendung .py zeigt an, dass dies eine Python-Quelltextdatei ist.
Fügen Sie dann folgende zwei Zeilen zu der Textdatei hinzu und speichern Sie Datei:
print("Hello World")
print("Hallo Python")
Sie können jetzt wieder das python3 Programm nutzen, um den Python-Code auszuführen.
Anstatt aber jede Zeile interaktiv einzutippen, geben Sie den relativen Pfad zur Datei als Argument des Programmaufrufs an.
python3 hello.py
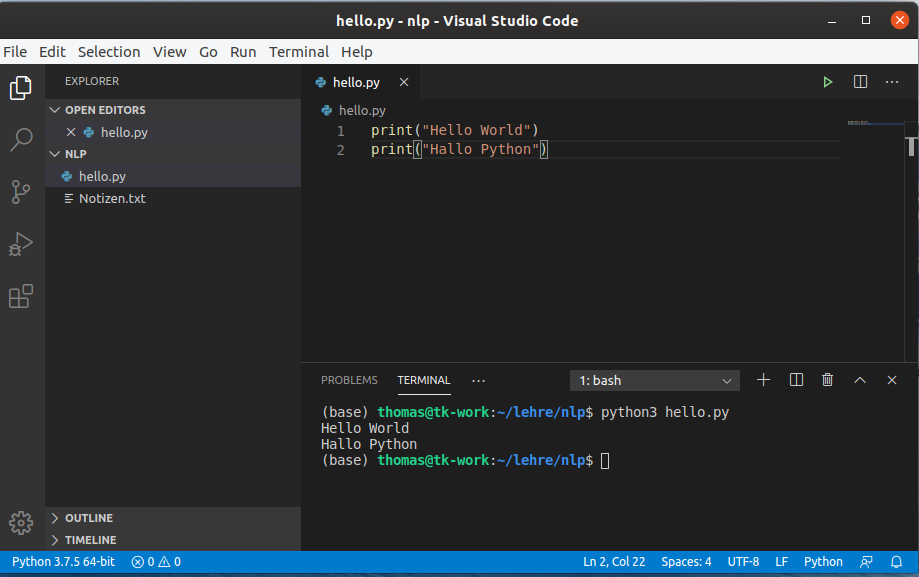
Herzlichen Glückwunsch, Sie haben ihr erstes eigenes Python-Programm ausgeführt! 🎉
Wenn eine Datei als Argument übergeben wird, wird python3 diese Anweisung für Anweisung ausführen und alle Ausgaben, die z.B. mit dem Python-Befehl print() gemacht werden ausgeben.
Hello World
Hallo Python
Kernpunkte
Einfache Ausdrücke können durch die interaktive Eingabe in der Python-Konsole ausgeführt werden.
Folgen von Anweisungen können in Quelltextdateien mit der Endung
.pyabgelegt und mit dem Programmpython3ausgeführt werden.
Einfache Ausdrücke, Datentypen und Variablen
Overview
Teaching: 50 min
Exercises: 0 minQuestions
Wie kann man einfache Ausdrücke in Python ausführen?
Was sind Datentypen und Variablen?
Objectives
Umgang mit der Python-Konsole
Datentypen, Werte und Variablen verstehen
Ganze Zahlen und Kommazahlen
In Programmen muss man immer wieder Dinge berechnen, zum Beispiel Häufigkeiten von Vorkommen von Wörtern. Python kann mit zwei Arten von Zahlen umgehen: ganzen Zahlen (Integer) und Kommazahlen (Float von „Gleitkommazahl“).
Zunächst wollen wir testen, wie die Python-Konsole auf Dateneingaben reagiert. Dafür tippen wir eine x-beliebige Zahl ein und drücken die Eingabetaste Return:
12
Der Python-Interpreter gibt nun folgende Ausgabe als Antwort:
12
Die Python-Konsole berechnet für uns den Wert 12. Das klingt nur so merkwürdig, weil es an ursprünglichen Wert 12 nichts mehr zu berechnen gibt, weshalb Ein- und Ausgabe identisch sind.
Trotzdem haben wir einen vollständigen Ausdruck (in Englisch „Expression“) an Python übergeben, den wir mit der Eingabetaste abgeschlossen haben.
12 lässt sich aber noch anders ausdrücken bzw. berechnen, z. B. durch
6+6
Die Python-Konsole gibt uns das Ergebnis der Operation „+“ zurück, angewendet auf 6 und 6.
12
Zum Verständnis: Wir haben der Python-Konsole das Input 6+6 gegeben und als Output 12 erhalten. Gleichzeitig haben wir der Operation + das Input (6,6) gegeben und als Output 12 erhalten.
Rechenoperationen
Es gibt folgende relevante Rechenoperationen in Python, die Operatoren sind in Klammern mit angebeben.
- Addition (
+) und Subtraktion (-) - Multiplikation (
*), Division (/) - ganzzahlige Division (
//), Modulo (%)
+ und - werden zusätzlich als Vorzeichenoperatoren verwendet, wobei wir + in diesem Sinne nicht benutzen werden.
-12
Wie in der Mathematik, haben auch in Python * und / Vorrang vor + und -.
Übung
Was ist die Ausgabe dieses Ausdrucks und warum?
-4*2+10Lösung
2Zuerst wird
-4*2ausgewertet, was-8ergibt. Danach wird mit+10addiert und das Ergebnis2angezeigt.
Klammern können genutzt werden, um die Reihenfolge der Operatoren explizit anzugeben.
-4*(2+10)
-48
Wenn wir dividieren, erhalten wir als Rückgabewert keinen Integer, sondern einen Float:
3/4
0.75
Das gilt auch, wenn der Dividend durch den Divisor teilbar ist und eigentlich eine ganze Zahl anstatt einer Kommazahl zurückgegeben werden könnte.
-10/5
-2.0
Der Operator erzeugt also immer einen Float als Rückggabewert.
Übung
Was berechnen die Operatoren
//und%? Finden Sie es für die folgenden Ausdrücke heraus!5//2 6//4 9//37%4 15%13 4%2Lösung
5//2=26//4=19//3=37%4=315%13=24%2=0Ganzzahlige Division (
//) gibt uns das Ergebnis der Division ohne Nachkommastellen als Integer (nicht: Float) zurück. Modulo-Rechnung (%) hingegen gibt uns den Rest der ganzzahligen Division zurück. Das heißt immer dann, wennadurchbteilbar ist, ista%bgleich 0. Diese zwei Operationen können in verschiedenen Anwendungsfällen sehr nützlich sein.
Variablen
Wir programmieren (u. a.), um Probleme zu lösen und uns eigene Rechenarbeit zu ersparen. Für komplexe Berechnungen nützt uns die simple Berechnung allein wenig, wir müssen ihr Ergebnis auch zwischenspeichern, um es weiter verwenden zu können. Hierfür gibt es Variablen.
- Variablen sind Namen für Werte.
- In Python wird das
=Symbol benutzt um eine Wert auf der rechten Seite einer Variable auf der linken Seite zuzuweisen. - Variablen werden erstellt, wenn ihnen ein Wert zugewiesen wird.
- Variablennamen können aus den Buchstaben a-z, A-Z (Groß- und Kleinschreibung wird unterschieden), Unterstrichen und Ziffern bestehen. Ziffern sind nicht als erstes Zeichen erlaubt. Variablen sollten mit Kleinbuchstaben anfangen.
zahl1 = 5
zahl2 = 7
Wir haben 5 in der Variable mit dem Namen zahl1 gespeichert, 7 in zahl2. Die Zuweisung eines Wertes zu einer Variable wird auch assignment genannt.
Was passiert, wenn wir anschließend folgenden Befehl ausführen?
zahl1+zahl2
Python evaluiert die Werte von zahl1 und zahl2 und addiert diese.
12
Und auch dieses Ergebnis können wir wieder in einer Variable speichern:
ergebnis = zahl1+zahl2
Übung
Wie können wir nun das Ergebnis der Addition ansehen? Versuchen Sie es auf der Python-Konsole.
Lösung
Sie müssen den Variablennamen als Ausdruck in die Konsole eingeben:
ergebnis
Variablen können einen leeren Wert annehmen, in denen ihnen der spezielle Wert
None zugewiesen wird.
ergebnis = None
ergebnis
Variablen vom Wert None erzeugen keine Ausgabe.
Frage(n)
Was passiert, wenn wir die folgende Zeilen nacheinander ausführen?
zahl1 Zahl2Lösung
>>> zahl1 5 >>> Zahl2 Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'Zahl2' is not definedWas hat das zu bedeuten? Wie können wir das „reparieren“? Was erfahren wir über Variablennamen?
Einfache eingebaute Funktionen
Sogenannte Funktionen haben einen Namen, es können ein odere mehrere Argumente in Klammern angegeben werden und sie liefern einen Wert zurück (mehrere Argumente werden durch Komma getrennt).
Zum Beispiel liefert die eingebaute Funktion mit dem Namen type eine Information über den Typ eines Werts oder Variable.
type(zahl1)
<class 'int'>
Der Rückgabewert zeigt an, dass es sich um eine Ganze Zahl (Integer) handelt.
Im Gegensatz dazu, liefert
type(3.141)
<class 'float'>
einen Rückgabe wert für eine Kommazahl (Float) zurück.
Mit der eingebauten Funktion isinstance(wert, klasse) kann man überprüfen, ob ein Wert bzw. eine Variable einen bestimmten Typ hat.
Der Rückgabewert ist dabei vom Typ bool, also ein Wahrheitswert, und kann True oder False sein.
isinstance(3, int)
True
isinstance(3.0, int)
False
Python ist eine dynamisch typisierte Programmiersprache.
Das heißt, die gleiche Variable kann unterschiedliche Typen wie Float oder Integer zugewiesen bekommen.
Mit type kann man den Typ herausfinden, aber es gibt auch Funktionen um explizit eine Variable zu einem anderen Typ zu überführen
(„casten“).
int(val)überführt eine Variable in eine Ganzzahlfloat(val)überführt eine Variable in eine Gleitkommazahl
pi = int(3.141)
type(pi)
<class 'int'>
pi
3
float(pi)
3.0
Es noch gibt eine Vielzahl weiterer, bereits eingebauter Funktionen in Python. Eine Listen davon finden Sie unter https://docs.python.org/3.7/library/functions.html Einige davon benötigen keine Eingabeargumente, trotzdem müssen in diesem Fall die Klammern mit angegeben werden.
Kommentare und Dokumentation
Kommentieren Sie ihren eigenen Code und dokumentieren Sie somit dessen Funktionsweise. Das erleichtert anderen und auch Ihnen, den Code später noch zu verstehen. Außerdem können auf diese Weise Voraussetzungen Ihres Programms an die Eingabe und eine Darlegung der Form des Outputs dargelegt werden. Kommentare im Code beginnen Sie mit einer #.
Ein Beispiel:
# Das ist ein Kommentar
# This is a comment
Sprache in Python-Skripten
Es ist üblich Kommentare und andere Element des Quelltexts in Englisch zu halten, da sie so für ein breiteres Publikum verständlich sind. Im Rahmen dieses Kurses können Sie das aber ignorieren. Sie sollten lediglich sicherstellen, dass Ihre Mit-Studierenden und Ihr Dozent Sie verstehen.
Kernpunkte
Einfache Ausdrücke können durch die interaktive Eingabe in der Python-Konsole ausgeführt werden.
Datentypen sind Kategorien von Werten
Unterschiedliche Ausdrücke können Werte mit unterschiedliche Datentypen erzeugen
Variablen speichern Werte
Variablen muss ein Wert zugewiesen werden bevor sie genutzt werden können
Variablen können in Ausdrücken benutzt werden.
Variablen haben Namen und diese Namen unterscheiden Groß- und Kleinschreibung
Zeichenketten und einfache Skripte
Overview
Teaching: 110 min
Exercises: 0 minQuestions
Wie kann ich Zeichenketten in Python eingeben und darstellen?
Wie kann ich auf diese oder Teile davon zugreifen?
Was muss ich beim Ausführen von Python-Skripten beachten?
Objectives
Verstehen des Datentyps
strTyps von Python
Zeichenketten als Wert definieren
Zeichenketten oder Strings sind Sequenzen von Zeichen die zur Repräsentation von Text verwendet werden.
Sie werden in Python gekennzeichnet mit umschließenden ' oder ". Folgende Befehle sind also äquivalent:
text = 'Ein Brötchen kostet 25 Cent'
text = "Ein Brötchen kostet 25 Cent"
Variablen mit einem Textwert haben den Typ str:
type(text)
<class 'str'>
Man kann allerdings nicht einen String mit ' beginnen und dann mit " schließen, oder umgekehrt
text = 'Ein Brötchen kostet 25 Cent"
File "<stdin>", line 1
text = 'Ein Brötchen kostet 25 Cent"
^
SyntaxError: EOL while scanning string literal
Zugriff auf Teile von Strings
Jedem Zeichen in einem String ist ein Index zugewiesen, der seiner Position in der Zeichenkette entspricht. Gezählt wird ab 0 und Leerzeichen werden nicht übersprungen:
| E | i | n | B | r | ö | t | c | h | e | n | k | o | s | t | e | t | 2 | 5 | C | e | n | t | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 |
Der in text gespeicherte String hat eine Länge von 27 Zeichen. Diese berechnen wir in Python mit der len Funktion:
len(text)
Es ist möglich auf Abschnitte bzw. einzelne Zeichen des Strings über den Index und eckige Klammern zuzugreifen. Probieren Sie es selbst:
text[6]
Zeichenkodierung in Python
Wir erkennen, dass Python keine Probleme mit Umlauten hat. Das liegt daran, dass in Python 3 (im Gegensatz zu Python 2) Strings standardmäßig in Unicode kodiert sind.
Frage(n)
Indexierung funktioniert auch mit negativen Zahlen:
text[-3]Was erhalten Sie für den negativen index
[-3], wie geht Python in solchen Fällen vor?Lösung
'e'Python gibt nicht das 3. Zeichen von vorne, sondern das 3. Zeichen vom Ende des Textes aus.
Frage(n)
Was passiert in folgendem Fall? Bevor sie es ausführen, was erwarten Sie?
text[30]Lösung
Sie erhalten eine Fehlermeldung, dass der Index außerhalb des korrekten Bereichs für diesen Textwert war.
Traceback (most recent call last): File "<stdin>", line 1, in <module> IndexError: string index out of range
Einen Abschnitt eines Strings (Substring) erhalten wir über einen Index [a:b] wobei a der Index des ersten Zeichens ist und b das Ende des Abschnitts beschreibt. a ist inklusiv, der a-te Buchstabe ist also selbst im Substring enthalten, b ist dagegen exklusiv, der b-te Buchstabe ist also nicht enthalten, nur der Buchstabe (mit Index b-1) davor.
text[0:3]
'Ein'
Frage(n)
Probieren Sie anhand eines Beispielstrings mit der Länge L folgende Dinge aus:
- Was passiert, wenn Sie a, b oder beide Grenzen weglassen?
- Was passiert, wenn b > Länge des Strings
- Was passiert, wenn a > Länge des Strings
- Was passiert, wenn a > b? Was wenn a == b?
- Was passiert, wenn a > 0 und b < 0?
- Was passiert, wenn a < 0 und b > 0?
Lösung
Wenn die erste Grenze a weggelassen wird, wird implizit das erste Zeichen (0) als Start angenommen.
text[:3]'Ein'Wenn dagegen die zweite Grenze b weggelassen wird, wird implizit das letzte Zeichen als Ende angenommen.
text[23:]'Cent'Das Weglassen beider Grenzen entspricht dem ganzen String, ohne Einschränkung für Beginn und Ende.
text[:]'Ein Brötchen kostet 25 Cent'Der End-Index wird immer implizit auf die Länge des Strings begrenzt. Ist der Größer, wird der String nur bis zum Ende des Strings zurück gegeben. Ist hingegen der Start-Index größer als die Länge des Texts, wird nur der leere String zurück gegeben.
text[4:123]'Brötchen kostet 25 Cent'text[123:]''Analog dazu, wird auch der leere String ausgegeben, wenn der Start-Index größer oder gleich dem End-Index ist.
text[123:4]''text[4:4]''Wenn der Start-Index a größer gleich 0 ist und der End-Index b negativ, wird der Teilstring vom Zeichen mit dem Index a bis zum b. Zeichen zählend vom Ende des Texts zurückgegeben.
text[4:-8]'Brötchen kostet'Das geht aber nur, solange der negative Wert nicht über den Anfang des mit a beginnenden Teilstrings “hinausragt”.
Wenn a < 0 und b > 0 ist, wird normalerweise eine leerer String zurückgegeben. Wenn das Ende b aber größer ist als die Länge des Strings, ist der Ausdruck äquivalent zu
text[-a:]und es werden die letzten a Zeichen des Teilstrings ausgeben.text[-4:10]''text[-4:100]'Cent'Wie Sie sehen, können negative Index sehr schnell sehr kompliziert und unerwartete Semantik mit sich bringen. Die Python-Dokumentation zu “Sequences” hat weitere Beispiele für komplexe Zugriffe über Indexes: https://docs.python.org/3.7/library/stdtypes.html?highlight=sequence#sequence-types-list-tuple-range. Solche komplexen Konstrukte werden ohne genaue Kenntnis der Python-Dokument sehr schnell sehr schwer verständlich und sollten vermieden werden.
Übung
Beschäftigen wir uns weiter mit dem oben erwähnten String, den wir in text gespeichert haben. Nehmen Sie an, Sie wollen die für Sie wesentliche Information aus Werbetexten wie „Ein Brötchen kostet 25 Cent“ extrahieren. Sie interessieren sich nur für das Produkt („Brötchen“) und den Preis („25 Cent“).
Vervollständigen Sie das folgende Codefragment so, dass diese Daten in den beiden Variablen
whatundhowmuchgespeichert werden.what = text howmuch = textLösung
what = text[4:12] howmuch = text[20:len(text)]
print-Funktion
In der interaktiven Konsole kann man den Namen einer Variable als Befehl eingeben und bekommt deren Wert angezeigt. Sobald wir nicht mehr interaktiv in der Konsole, sondern mit Python-Skripte arbeiten, wird uns das nicht mehr weiterhelfen. Wir benötigen eine Funktion, mit der wir Variablen explizit ausgeben können.
Die Funktion print nimmt als Eingabe Daten vom Typ String und gibt diese auf der Konsole aus. Das einzige Argument der Funktion wird dabei in Klammern angegeben. Versuchen Sie es selbst:
print(what)
Sie können print auch mehrere Strings übergeben.
Diese werden durch ein Zeichen (Standard: Leerzeichen) getrennt ausgegeben. Das Trennzeichen kann über den Parameter sep manipuliert werden.
sep ist ein benannter Parameter, das heißt man gibt in den Klammern nicht nur den Wert an, sondern schreibt sep= davor.
print(what,howmuch)
Brötchen 25 Cent
print(what,howmuch,sep=";")
Brötchen;25 Cent
Ausführen mehrerer Anweisungen in einem Skript
Wie wir bereits im 1. Kapitel gesehen haben, können wir anstatt Anweisungen für ein Programm interaktiv in der Konsole auszuführen sie auch in eine Textdatei mit der Endung .py schreiben.
Der Befehl python3 dateiname.py auf der Konsole führt diese Anweisungen dann hintereinander aus.
Wird das Programm beendet, werden auch alle Variablen vergessen.
Jeder Aufruf vom Python-Interpreter startet also immer ohne definierte Variablen, erst durch die einzelnen Ausführungsschritte im Skripts werden die Variablen definiert und mit Werten belegt.
Bei der Entwicklung testet man oft kurze Code-Stücke in der interaktiven Konsole, die man dann in ein Skript überträgt.
Windows
Windows enthält standardmäßig kein Python und die Unterscheidung in Version 2 und 3 ist daher nicht so relevant. Nach einer systemweiten Installation und der Eintragung von der Python-Installation in die Systemvariable
PATHoder mitconda activatekann man daher unter Windows mit dem Befehlpython(also ohne die Versionsnummer „3“) auf der Kommandozeile starten.
Übung
Nutzen Sie einen Texteditor um ein Programm zu schreiben, dass folgende Anweisungen hintereinander ausführt und führen sie dies aus.
- Berechne die Summe von 100 und 123
- Gebe die Zeichenkette “100+123=???” wobei „???“ für das Ergebnis steht.
Lösung
# Dieser Text steht in der Datei summe.py summe = 100+123 print("100+123",summe,sep="=")python3 summe.py100+123=223
Strings verketten
Wenn wir zwei Strings miteinander zu einem neuen String verbinden wollen (konkatenieren), so nutzen wir den „+“-Operator, den wir schon von den Zahlenoperationen kennen.
stem_1 = 'Haus'
stem_2 = 'boot'
comp = stem_1 + stem_2
print(comp)
Hausboot
Wollen wir eine Zeichenkette n mal vervielfachen, so können wir sie einfach mit n multiplizieren:
result = 'Nomen'*10
print(result)
NomenNomenNomenNomenNomenNomenNomenNomenNomenNomen
Strings können aus anderen Datentypen über die Konvertierungsfunktion str(val) erzeugt werden.
Damit kann man z.B. auch einen String mit einer Zahl verketten
zahl = 13+13
result = "Die Zahl ist " + str(zahl)
print(result)
Die Zahl ist 26
String-Methoden
Wir wollen uns einen Überblick über die wichtigsten Methoden für String-Variablen ansehen.
Aber was sind denn nun wieder Methoden?
In dieser Episode nur so viel: Methoden sind Funktionen, die wir an einer Variable (genauer: einem Objekt) mit Hilfe eines . direkt aufrufen.
Hier ein Beispiel:
var = "Huch"
print(var) # Funktion
var.strip() # Methode
strip()
Diese Methode ist z. B. wichtig bei der Bereinigung unserer Eingabe. Sie entfernt Leerzeichen, Zeilenumbrüche (\n in Linux), Tab-Einrückungszeichen (\t) und andere White-Space-Zeichen am Anfang und Ende des Strings. Sie verändert nicht die Variable, an der sie aufgerufen wird, sondern gibt einen neuen String zurück.
txt = "\tWas macht strip()? "
txt_no_whitespaces = txt.strip()
print("|" + txt + "|")
| Was macht strip()? |
print("|" + txt_no_whitespaces + "|")
|Was macht strip()?|
find(seq) und rfind(seq)
Wenn wir eine Sequenz von 1 und mehr Zeichen in einem String suchen wollen, geben uns diese Methoden die Stelle (als Integer) im String zurück,
an der die Sequenz beginnt.
find(seq) gibt uns den ersten Treffer von links, rfind(seq) entsprechend von rechts.
Ausgegeben wird die Stelle des ersten Zeichens der gesuchten Sequenz.
haystack = 'Heu Nadel Heu Heu Nadel Heu'
l = haystack.find('Nadel')
r = haystack.rfind('Nadel')
print(l,r)
4 18
Übung
Bearbeiten Sie den folgenden Abschnitt so, dass aus
infonur der Text zwischen „Achtung“ und „egal“ ausgegeben (über dieinfo = "bla bla bla Achtung Wichtig egal bla bla bla" # Ihr Code:Lösung
wichtig_l = info.find("Achtung") + len("Achtung") wichtig_r = info.rfind("egal") print(info[wichtig_l:wichtig_r].strip())Wichtig
replace(is, willbe)
Mit dieser Methode wird eine Zeichensequenz in einem String an jeder Stelle ihres Vorkommens durch eine andere ersetzt. Das Ergebnis wird als neuer String zurückgegeben.
In folgendem Beispiel sollen aus dem Input-String „ß“ und Umlaute entfernt und durch Alternativen ersetzt werden:
messy_input = "Sie wohnen in der Hauptstraße. Das ist ungewöhnlich."
clean_input = messy_input.replace("ß","ss").replace("ö","oe").replace("ä","ae").replace("ü","ue")
print(clean_input)
Sie wohnen in der Hauptstrasse. Das ist ungewoehnlich.
Frage(n)
- Warum kann
replaceeinfach mehrmals hintereinander aufgerufen werden?- Was passiert, wenn ein String eine zu ersetzende Zeichensequenz nicht enthält?
Lösung
Die Methode
replaceliefert als Rückgabewert wieder einen neuen String zurück und auf Strings kann man die Methodereplaceausführen. Man muss nicht zwingend den Rückgabewert in eine Variable zwischenspeichern, um ihn zu nutzen.Wenn die gesuchte Zeichensequenz nicht vorkommt, wird der unveränderte Original-String zurückgegeben.
messy_input.replace("Berlin", "Brandenburg")'Sie wohnen in der Hauptstraße. Das ist ungewöhnlich.'
Übung
Schreiben Sie einen „Übersetzer“, der den String german ins Englische übersetzt.
german = "Die Katze ist schwarz" # Ihr Code engl =Überlegen Sie kurz, ob dieses Vorgehen generell, also für eine beliebige deutsche Eingabe, sinnvoll ist.
Lösung
Wir können im Moment nur kontextunabhängig einzelne Strings ersetzen. Für das konkrete Beispiel reicht das schon, auch wenn wir natürlich kein Zugriff auf ein Lexikon oder syntaktische und semantische Informationen haben und nicht einmal Wörter erkennen oder sogar die Wortstellung umschreiben können.
german = "Die Katze ist schwarz" engl = german.replace("Die", "The").replace("Katze", "cat").replace("ist", "is").replace("schwarz", "black") print(engl)The cat is black
startswith und endswith
Die beiden Funktionen überprüfen, ob ein String mit einem Prefix beginnt oder einem Suffix endet.
satz = "Ein Wort ist kein Satz."
print(satz.startswith("Ein"))
print(satz.endswith("!"))
True
False
Kernpunkte
Strings sind Sequenzen von Zeichen auf die über einen Index zugegriffen werden kann.
Es gibt Methoden, die Operationen auf diesen Zeichenketten ausführen, wie z.B. finden und ersetzen.
Variablen werden nur innerhalb eines Aufrufs des Python-Interpreters gespeichert.
Kontrollstrukturen und Listen
Overview
Teaching: 110 min
Exercises: 30 minQuestions
Wie können Sequenzen von Werten gespeichert werden?
Wie kann ich Code mehrfach ausführen?
Wie kann ich Code nur unter einer bestimmten Bedingung ausführen?
Objectives
Verständnis von wichtigen Hilfsdatentypen und Methoden für Kontrollstrukturen
Verstehen von Kontrollstrukturen wie Schleifen und Bedingungen
Ausdrücken von logischen Bedingungen
Listen
Eine Liste ist eine veränderbare Sequenz von Werte. Sie kann gleiche Elemente mehrmals enthalten. Zudem sind die einzelnen Elemente in einer festen Reihenfolge angeordnet, jedes Element hat einen Index, der dessen Platz in der Liste entspricht. Die Elemente einer Liste mit der Länge L können über die Indizes 0..L-1 angesprochen werden. Das kennen wir bereits von Strings.
l = [] # wir initialisieren eine leere Liste
l.append(1) # wir fügen der Liste Elemente hinzu
l.append("Piano")
l.append(1.42)
print(l)
[1, 'Piano', 1.42]
Länge einer Liste:
print(len(l))
3
Abruf eines einzelnen Elements:
print(l[0])
1
Abruf einer Unterliste:
print(l[0:len(l)-1])
[1, 'Piano']
Frage(n)
- Welchen Typ hat
l?- Welchen Typ hat
l[0:2]?- Welchen Typ haben
l[0],l[1]undl[2]?Lösung
Zum beantworten müssen Sie die Funktion
type()auf den jeweiligen Ausdrücken ausführen.type(l) type(l[0:2]) type(l[0]) type(l[1]) type(l[2])Die ersten beiden Ausdrücke geben die gesamte Liste oder eine Teilliste zurück. und liefern als Rückgabe der
type()-Funktion den Typlistfür Listen in Python zurück. Wenn nur auf einzelne Element der Liste zurückgegriffen wird, wie in den letzten drei Aufrufen, wird der eigentliche Wert der an dieser Listenposition steht zurückgegeben. Damit liefert auch dietype()-Funktion den Typ des Werts, hier alsoint,strundfloat, zurück.
Es können nicht nur neue Elemente hinzugefügt, sondern auch bestehende Elemente entfernt werden.
l.remove("Piano") # wir entfernen ein Element aus der Liste (nach Wert)
l.pop(0) # wir entfernen ein Element aus der Liste (nach Index)
print(l)
[1.42]
Es gibt auch weitere nützliche Methoden auf Listen.
Zählen der Anzahl der Elemente mit gegebenen Wert in einer Liste mit count:
a = [1,4,7,3,4,4]
a.count(4)
3
Umgekehrte Reihenfolge mit reverse:
a = [1,7,3,4]
a.reverse()
print(a)
[4, 3, 7, 1]
Sortierung mit sort:
a.sort()
print(a)
[1, 3, 4, 7]
Einfügen an angebenen Index (und nicht nur anhängen):
a.insert(2,10)
print(a)
[1, 3, 10, 4, 7]
Entfernen des letzten Elements mit pop() (ohne Argument):
e = a.pop()
print("popped", e, ", list is", a)
popped 7 , list is [1, 3, 10, 4]
Löschen des Inhalts einer Liste:
a.clear()
print(a)
[]
For-Schleifen
Mit dem Ausdruck for x in var: kann man den gleichen Code-Block auf jedem Element x der Liste var ausführen.
Ein Code-Block sind Anweisungen, die mit der gleichen Anzahl Leerzeichen eingerückt sind.
Der Code-Block wird also wiederholt.
l = [1, 2, 3, 4, 5]
for x in l:
print("Element")
print(x)
Element
1
Element
2
Element
3
Element
4
Element
5
Einrückung mit Leerzeichen oder Tabs?
Für die Einrückung eines Codeblocks können entweder Leerzeichen oder Tabs verwendet werden. Viele Texteditoren ersetzen eine Eingabe mit der Tab Taste auf der Tastatur automatisch mit einer bestimmten Anzahl Leerzeichen. Da Tabs ebenfalls als „Whitespace“ angezeigt werden, ist es schwierig diese auseinanderzuhalten. In alten Python-Versionen konnten Leerzeichen und Tabs im selben Skript gemischt werden, was zu Verwirrung und Fehlern bei unterschiedlich tief eingerückten Code-Blöcken geführt hat. In Python 3 ist das Mischen verboten.
Es bleibt natürlich die Frage, was besser ist. Darauf gibt es keine wirklich ultimative Antwort und diese Frage wird in entsprechenden Foren immer wieder stark diskutiert. Die „Style Guide for Python Code“ empfielt in neuem Code Leerzeichen zu verwenden: https://www.python.org/dev/peps/pep-0008/#tabs-or-spaces
Anstatt über eine Liste, können for-Schleifen auf sogenannten Iteratoren ausgeführt werden.
Iteratoren sind Datenstrukturen, die basierend auf einem aktuellen Zustand einen neuen Zustand berechnen und zurückgeben können.
Die Funktion range(a,b) liefert einen Iterator zurück, der nacheinander alle Zahlen von a bis b (exklusive b) ausgibt.
Übung
Formulieren Sie
for-Schleife von weiter oben so um, dass sie dierangeFunktion anstatt der Liste benutzt, aber die gleiche Ausgabe erzeugt.Lösung
for x in range(1,6): print("Element") print(x)
Iteratoren haben gegenüber von Listen den Vorteil, dass sie nicht alle Element speichern müssen. Wenn wir z.B. alle Zahlen von 1 bis 1.000.000 aufaddieren wollen, würde das viel Speicher belegen, wenn wir eine Liste mit einer Million Zahlen anlegen müssten. Mit einem Iterator wird immer nur ein kleiner Zustand (die aktuelle Zahl und das Ende des Bereichs) gespeichert.
summe = 0
for i in range(1,1_000_001):
summe = summe + i
print("Summe ist: " + str(summe))
Summe ist: 500000500000
Tausendertrennzeichen im Code
Um große Zahlen übersichtlicher eingeben zu können, ist seit Python 3.6 im Python-Code
_als Tausendertrennzeichen erlaubt.
Der Name der Schleifenvariable kann frei gewählt werden.
Für Indexe hat sich oft i eingebürgert, aber sollte möglichst sprechende Namen für Variablen verwenden.
for hier_kann_wirklich_alles_stehen in range(0,11):
print(hier_kann_wirklich_alles_stehen)
0
1
2
3
4
5
6
7
8
9
10
For-Schleifen und andere Kontrollstrukturen können verschachtelt werden, das heißt in einem for-Block können z.B. auch weitere for-Blöcke stehen.
Die tiefere Verschachtelung eines Code-Blocks wird durch die größere Anzahl an Leerzeichen/Tabs ausgedrückt:
for i in range(1,4):
for j in range(1,4):
summe = i + j
produkt = i * j
print(i, "+", j, "=", summe)
print(i, "*", j, "=", produkt)
1 + 1 = 2
1 * 1 = 1
1 + 2 = 3
1 * 2 = 2
1 + 3 = 4
1 * 3 = 3
2 + 1 = 3
2 * 1 = 2
2 + 2 = 4
2 * 2 = 4
2 + 3 = 5
2 * 3 = 6
3 + 1 = 4
3 * 1 = 3
3 + 2 = 5
3 * 2 = 6
3 + 3 = 6
3 * 3 = 9
Einfache logische Bedingungen und der Datentyp bool
Neben Strings und Zahlen hat Python auch einen Datentyp für Wahrheitswerte.
Eine Variable mit Wahrheitswerten kann entweder den Wert True oder False haben.
stimmt = False
type(stimmt)
<class 'bool'>
stimmt = True
print(stimmt)
True
Man kann Wahrheitswerte durch den Vergleich von anderen Werte über bestimmte Operatoren erhalten.
Z.B. kann man zwei Zeichenketten mit dem == Operator vergleichen, ob sie identisch sind:
"Haus" == "Haus"
True
Das Ergebnis eines Vergleichs kann auch wieder in einer Variablen gespeichert werden:
gleiches_haus = "Haus" == "Haus"
print(gleiches_haus)
True
==ist nicht gleich=Der Vergleichsoperator
==ist nicht mit dem Zuweisungsoperator=zu verwechseln. Letzerer weist einer Variable einen Wert zu und lieft nicht einen logischen Wert zurück. Z.B. ist folgender Ausdruck ein Fehler:"Haus" = "Haus"File "<stdin>", line 1 SyntaxError: can't assign to literal
Bei einem Vergleich ist der Wert der Variablen oder des Ausdrucks entscheidend, nicht die Form.
Z.B. liefern auch alle folgenden Vergleiche True zurück.
"Haus" == 'Haus'
var = 'Haus'
"Haus" == var
0.0000 == 0.0
Wertevergleiche sind exakt, dass heißt z.B. das bei Groß- und Kleinschreibung von Zeichenketten oder bei Whitespace (Leerzeichen, Tabs, Zeilenumbrüche etc.) unterschieden wird.
"Haus" == "haus"
False
"Haus" == "Haus "
False
Übung
Wie können die beiden Zeichenketten
"Haus"und"Haus "mitTrueals Ergebnis verglichen werden?Lösung
"Haus" == "Haus ".strip()
Analog zum == Operator gibt es den != Operator, der immer dann wahr ist wenn zwei Werte unterschiedlich sind.
4 != 1
True
Wenn-Dann-Blöcke
If-Ausdrücke
Wir haben nur einfache logische Bedingungen mit dem == Operator kennengelernt.
Logische Bedingungen können genutzt werden, um Code-Blöcke basierend auf dem Wahrheitswert auszuführen, oder aber nicht.
x = 5
if x == 4:
print("x ist vier!")
Dieses Programm erzeugt keine Ausgabe, weil die Bedingung nicht wahr ist. Wenn die Bedingung wahr ist, wird der Code-Block ausgeführt.
if x == 5:
print("x ist fünf!")
x ist fünf!
Die Ein Code-Block kann aus mehr als einer Anweisung bestehen und nach dem eingerückten if-Block wird der orginale Code-Block weiter ausgeführt,
egal ob die Bedingung wahr oder falsch war.
x = 5
if x == 4:
x = x + 2
print("x wahr vier, neuer Wert ist", x)
x = x - 1
print("x ist", x)
x ist 4
x = 5
if x == 5:
x = x + 2
print("x wahr fünf, neuer Wert ist", x)
x = x - 1
print("x ist", x)
x wahr fünf, neuer Wert ist 7
x ist 6
If-Else Ausdrücke
Diese Konstruktion erlaubt die Überprüfung einer Bedingung.
Falls die Bedingung wahr ist, wird der Code-Block hinter der if-Anweisung ausgeführt, ansonsten der Block hinter
der else: Anweisung:
x = 5
if x == 4:
print("x ist vier")
else:
print("x ist ein anderer Wert")
x ist ein anderer Wert
If-Elif(-Else)
Man kann beliebig viele Ausdrücke überprüfen, in dem man zusätzliche elif Bedingungen hinzufügt:
x = 3
if x == 1:
print("x ist eins")
elif x == 2:
print("x ist zwei")
elif x == 3:
print("x ist drei")
elif x == 4:
print("x ist vier")
x ist drei
Auch an diese Ausdrücke kann ein else angehängt werden:
x = 100
if x == 1:
print("x ist eins")
elif x == 2:
print("x ist zwei")
elif x == 3:
print("x ist drei")
elif x == 4:
print("x ist vier")
else:
print("x ist ein anderer Wert")
x ist ein anderer Wert
Es wird immer der erste Ausdruck ausgewertet der wahr ist, die anderen werden ignoriert.
if 2==1:
print("Mathematik kaputt")
elif 1==1:
print("Mathematik geht")
elif 2==2:
print("Mathematik geht immer noch")
else:
print("Zustand von Mathematik unbekannt")
Mathematik geht
While-Schleifen
Man kann logische Bedingungen auch in While-Schleifen verwenden, um einen Block zu wiederholen, solange eine Bedingung erfüllt ist.
x = 0
while x != 10:
print(x)
x = x + 1
0
1
2
3
4
5
6
7
8
9
Frage(n)
Was passiert wenn die Bedingung immer wahr ist, z.B. in:
while 1 == 1: print("Mathematik in Ordnung")Lösung
Es wird eine sogenannte Endlosschleife erzeugt, die sich nicht mehr beendet. Sie können nur das gesamte Programm (also den Python-Interpreter) von außen beenden um die Ausführung der Schleife zu unterbrechen.
Programm im Terminal beenden
Falls Sie ein Programm im Terminal beenden wollen, können Sie Strg+C drücken.
Übung
Schreiben Sie ein kurzes Programm, das eine Liste aller Zahlen zwischen 1 und 999, die ohne Rest durch 13 teilbar sind, erstellt. Das Programm soll die Liste am Ende ausgeben.
Lösung
Mögliche Lösung:
zahl13 = [] for i in range(1,1000): if i % 13 == 0: zahl13.append(i) print(zahl13)
Arithmetische Vergleichsoperatoren
Neben == und != gibt es für Zahlen noch weitere Operatoren:
<für „echt kleiner als“<=für „kleiner gleich“>für „echt größer als“>=für größer gleich“
print(2 < 2)
print(2 <= 2)
print(10 > 1)
print(10 >= 1)
False
True
True
True
Übung
Schreiben Sie ein kurzes Programm, das eine Liste aller Zahlen zwischen 1 und 999, die ohne Rest durch 13 teilbar sind, erstellt. Nutzen Sie dafür den
<Operator! Diskutieren Sie die Vor- und Nachteile im Vergleich zur Ihrer Version weiter oben.Lösung
zahl13 = [] x = 13 while x < 1000: zahl13.append(x) x = x + 13 print(zahl13)Im Vergleich zur vorherigen Lösung muss noch mehr darauf geachtet werden, dass die Abbruchbedingung wirklich ausgelöst wird um keine Endlosschleife zu erstellen. Endlosschleifen sind mit
fordeutlich einfacher zu vermeiden. Allerdings ist diese Lösung womöglich performanter. In derfor-Schleife wurde tausend mal überprüft, ob eine Zahl durch 13 teilbar ist. Diese Anweisung benötigt Ausführungszeit auf dem Prozessor. Die Anweisungen in derwhile-Schleife wird nur genau so oft ausgeführt, wie es Zahlen gibt die an die Liste angehängt werden müssen (also deutlich weniger als 1000 mal). Es ist in diesem Fall möglich, die Vorteile derfor- mit denen derwhile-Schleife zu verbinden. Dazu muss bei derrange()Funktion der optionalestepParameter mit angeben werden:zahl13 = [] for i in range(13,1000, 13): zahl13.append(i) print(zahl13)
Logische Formeln
Logische Ausdrücke können wie auch logische Formeln mit and, or und not verknüpft werden
a = True
b = False
implikation = not a or b
Klammern können genutzt werten um explizit die Reihenfolge der Vergleichsoperatoren anzugeben
if (1 != 1 and 1 == 4) or ((2+1) == 4):
print("Mathematik schon wieder kaputt")
else:
print("Mathematik geht noch")
Übung
Bilden Sie aus den gegebenen den folgenden drei Variablen den komplexen Wahrheitswert
social_security. Dieser sagt aus, ob wir noch Kindergeld erhalten. Hier die genauen Bedingungen:
- Wenn wir minderjährig sind, gibt es Kindergeld
- Wenn wir nicht mehr minderjährig, aber jünger als 25 sind und studieren, gibt es Kindergeld
- Wenn wir älter als 24 sind und ein FSJ (freiwilliges soziales Jahr) absolviert haben, bekommen wir Kindergeld (wir ignorieren, dass das zeitlich begrenzt ist)
age = 24 studying = False fsj = True social_security = # TODO: logischer AusdruckLösung
age = 24 studying = False fsj = True social_security = (age < 18) or (age < 25 and studying) or (age > 24 and fsj)
Interaktive Eingabe
Wir kennen bereits print(var) um Informationen auszugeben.
Das Gegenstück dazu die Funktion input().
Sie erlaubt einem Python-Skript, Texteingaben vom Nutzer entgegenzunehmen.
print("Hallo, meine Name ist Script!")
name = input("Wie heißen Sie? ")
print("Hallo " + name + "!")
Dieses Script erzeugt erst die Ausgabe
Hallo, meine Name ist Script!
Wie heißen Sie? ▮
Das Argument von input() ist ein sogenannter “Prompt”, also eine Eingabeaufforderung an den Nutzer.
Der Prompt wird ausgegeben und es wir solange gewartet, bis der Nutzer eine Eingabe gemacht und diese mit der Eingabetaste Return abgeschlossen hat.
Die Funktion liefert die Eingabe als Typ String zurück.
In diesem Beispiel wird die Rückgabe in eine Variable geschrieben und wieder ausgegeben.
Hallo, meine Name ist Script!
Wie heißen Sie? Thomas
Hallo Thomas!
Übung
Schreiben Sie ein Skript das folgendes tut: Das Skript hat eine interne „magic number“, die Sie frei wählen können. Fragen Sie den Nutzer, wie die Nummer ist. Geben Sie ihm Feedback, ob die Zahl die er geraten hat größer oder kleiner als die „magic number“ ist. Wenn der Nutzer die Zahl erraten hat, gratulieren Sie ihm und beenden das Programm.
Lösung
Mögliche Lösung:
magic_number = 355 guessed = None while guessed != magic_number: guessed = input("Bitte Nummer raten: ") guessed = int(guessed) if guessed < magic_number: print("Zu klein!") elif guessed > magic_number: print("Zu groß!") print("Herzlichen Glückwunsch, Sie haben die Nummer erraten!")
Kernpunkte
Sequenzen von beliebigen Werten können in Listen gespeichert und abgerufen werden.
Logische Ausdrücke haben in Python den Datentyp
boolund können unter anderem durch Vergleichsoperatoren erzeugt werden.Mit Schleifen (
for,while) und bedingt ausgeführten Code-Blöcken (if-elif-else) kann der Programmablauf flexibel auf die Eingabe reagieren und komplexere Berechnungen durchführen.
Eigene Funktionen und Module
Overview
Teaching: 60 min
Exercises: 0 minQuestions
Wie kann ich selbst eigene Funktionen definieren?
Wie können Funktionen aus externen Bibliotheken eingebunden werden?’
Objectives
Funktionalität von Programmen nachnutzen
Eigene Funktionen definieren
Bisher haben wir uns nur mit einfachen Anweisungen beschäftigt. Typischerweise wollen wir aber nicht immer wieder neu die gleichen Algorithmen an verschiedenen Stellen implementieren, sondern unser Programm soll eine komplexe Anweisung auf einmal ausführen. Dafür müssen wir unseren Code als eigene Funktion definieren:
def add_mult(a, b):
output = a + b
output = output + (a * b)
return output
Eine Funktion besteht aus der Funktionsdefinition, die mit den Schlüssewort def eingeleitet und mit dem Doppelpunkt abgeschlossen wird.
Darin steht der Name der Funktion (hier add_mult) und die Namen der Argumente, abgetrennt durch Komma.
In dem Beispiel werden zwei Argumente a und b übergeben.
Der Funktionsdefinition folgt ein Code-Block, der die Funktion implementiert.
Der Block ist hier mit der return Anweisung abgeschlossen, die die Funktion beendet und den Rückgabewert definiert.
Nachdem eine Funktion definiert ist, kann sie im Code aufgerufen werden, genauso wie die eingebauten Funktionen auch.
v = add_mult(1, 100)
print(v)
Übung
Schreiben Sie eine Funktion, die gegeben zweier Werte die Summe aller Zahlen zwischen dem ersten und dem zweiten Wert (inklusive) angibt. Rufen Sie diese Funktion für verschiedene Werte auf und geben Sie die Werte aus. Für z.B. die Argumente 5 und 13 soll die Funktion die Summe 5 + 6 + 7 + 8 + 9 + 10 + 12 + 13 = 81 berechnen.
Lösung
def complex_math(start, end): summe = 0 for i in range(start, end+1): summe = summe + i return summe print(complex_math(5,13)) print(complex_math(1,100)) print(complex_math(20,100)) print(complex_math(1,10))81 5050 4860 55
Funktionen können Werte von verschiedenen Typen als Argument bekommen.
Auch kann die gleiche Funktion verschiedene Typen von Werten zurückgeben und je nach Bedingungen verschiedene
return Anweisungen ausführen (es wird aber immer nur die erste return Anweisung ausgeführt).
def fancy_add(val):
if isinstance(val, str):
return val + " + 1"
elif isinstance(val, int):
return val + 1
elif isinstance(val, float):
return val + 1.0
else:
return 42
print(fancy_add(2))
print(fancy_add(2.0))
print(fancy_add("2"))
print(fancy_add(False))
3
3.0
2 + 1
1
Der Code nutzt die eingebaute Funktion isinstance um zu überprüfen, ob eine Variable einen gegebenen Typ hat.
Außerdem ist es möglich, dass eine Funktion mehr als einen Wert zurückgibt.
In diesem Fall muss die return Anweisung alle Werte mit Komma getrennt auflisten.
Die Zuweisung von mehreren Werten beim Aufruf einer Funktion erfolgt ebenfalls durch Auflistung mit Komma.
def get_str_info(text):
l = len(text)
c = text[0]
return l, c
a, b = get_str_info("This is an arbitrary string, I swear")
36
T
Frage
Was bedeuten die Werte, die die Funktion zurückliefert?
In Python wird unterschieden zwischen positionalen Argumenten, die übergeben werden müssen und Keyword-Argumenten, die optional sind und für die ein Standard-Wert in der Funktions-Definitions angegeben werden kann, der genutzt wird wenn das Argument nicht übergeben wird. Hier ein Beispiel:
def print_log(log_text, with_exclamation_marks=False):
if with_exclamation_marks:
print('!!! '+log_text+' !!!')
else:
print(log_text)
print_log('Nothing happend.')
print_log('Alarm', with_exclamation_marks=True)
print_log('Alarm', True)
Nothing happend.
!!! Alarm !!!
!!! Alarm !!!
Der Standardwert für das Argument with_exclamation_marks ist hier False.
Module und der import Befehl
Eigene Module
Jede Python-Datei ist gleichzeitig eine sogenanntes Modul.
Man z.B. kann man das folgende Python-Skript mit dem Namen poornlp.py abspeichern:
def get_str_info(text):
l = len(text)
c = text[0]
return l, c
def is_noun(word):
return word[0].isupper()
Dieses enthält jetzt die beiden Funktionen get_str_info und is_noun.
Durch das Speichern in der Datei haben wir ein Modul gleichen Names (poornlp) erzeugt.
Nun wollen wir diese Funktionen ja nachnutzen und nicht jedes mal in unsere Skripte kopieren.
Zum Laden der Funktion in ein eigenes Skript oder in die interaktive Konsole kann man den import Befehl benutzen.
Angenommen, das Skript mit dem Modul befindet sich im gleichen Ordner, dann kann man
import poornlp
aufrufen und bekommt Zugriff auf die beiden Funktionen über den Modulnamen, gefolgt von einem .:
poornlp.get_str_info("Das ist ein Text")
Möchte man eine bestimmte Funktion aus einem Modul importieren, geht das mit from ... import:
from poornlp import get_str_info
Danach ist es nicht mehr notwendig, für die importierte Funktion den Modulenamen anzugeben:
get_str_info("Das ist ein Text")
Wenn das Modul in einem Unterordner liegt, kann man ebenfalls durch import darauf zugreifen, muss aber wieder einen Punkt zwischen dem Elternmodul (dem Ordner) und dem Kindermodul angeben.
Z.B. sei eine Ordnerstruktur mit einem Ordner mathmodules und zwei Python-Dateien in dem Ordner gegeben
mathmodules/
├── basic.py
└── fancy.py
basic.py:
def add(a,b):
return a + b
fancy.py:
def add(val):
if isinstance(val, str):
return val + " + 1"
elif isinstance(val, int):
return val + 1
elif isinstance(val, float):
return val + 1.0
else:
return 42
Der Import für basic sehe dann folgendermaßen aus:
import mathmodules.basic
mathmodules.basic.add(5,10)
Auch Untermodule müssen importiert werden, z.B. würde
mathmodules.fancy.add("A")
fehlschlagenn wenn nur mathmodules oder mathmodules.basic, aber nicht mathmodules.fancy importiert worden ist.
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: module 'mathmodules' has no attribute 'fancy'
Manchmal sind die Modulnamen sehr lang, dann kann man über import ... as ... abgekürzt werden
import mathmodules.basic as mb
mb.add(42,3.13)
Ähnliches geht auch, wenn man Funktionsnamen mit from ... import ... as ... importiert, was sogar eine Umbennung der Funktion erlaubt und hilft Namenskonflikte aufzulösen:
from mathmodules.fancy import add as fancy_add
fancy_add(42)
Standardbibliotheken und Installation von neuen Bibliotheken
Python besitzt neben den eingebauten Funktionen und Typen auch noch eine riesige sogenannte Standardbibliothek. Dies sind Module, die in allen Python-Installationen (für eine bestimmte Version von Python) immer vorhanden sind. Sie können also erwarten, dass Sie in jedem Skript diese Module importieren können.
Eine Auflistung und Dokumentation der Module der Standardbibliothek findet sich unter https://docs.python.org/3.7/library/index.html.
Reguläre Ausdrücke auf Strings mit Modul re
Ein Beispiel für eine sehr nützliches Module aus der Standardbibliothek ist das Modul für reguläre Ausdrücke (also Mustersuche) mit dem Namen re.
Muster oder „Patterns“ müssen erst einmal erstellt („kompilliert“) werden und kann dann auf Strings angewendet werden.
import re
pattern = re.compile('Glü.+')
# gibt nicht None zurück, wenn der ganze String dem Pattern matched
is_match = pattern.match("Was für ein Glück")
# gibt nicht None zurück, wenn ein Teilstring dem Pattern matched
found = pattern.search("Was für ein Glück")
# Überprüfe ob die jeweiligen Ergebnisse nicht None sind
if is_match:
print('It is a full match!')
elif found:
print('I found it somewhere!')
print("Found string =", found.group(0))
I found it somewhere!
Found string = Glück
Auf der Dokumentation des Moduls re gibt es eine Einführung in die Syntax dieser Patterns und wie man nicht nur ja/nein Suchen sondern auch die Position des Treffers bekommen kann.
Installation neuer Pakete mit pip
Hilfreiche allgemeine Python-Pakete, können über den „Python Package Index“ unter
https://pypi.org gefunden werden.
Die Installation auf dem lokalen System erfolgt dann mit dem Kommandozeilentool
pip.
Um pip nutzen zu können, müssen Sie es unter Umständen erst in Conda installieren.
Führen Sie dazu in Ihrer System-Kommandozeile mit aktiviertem Conda (z.B. im VS Code Terminal), folgenden Befehl aus:
conda install pip
Wenn Sie die Installation bestätigen, können Sie danach mit pip list eine Liste aller bereits installierte Pakete aufrufen.
pip list
Package Version
---------------------- ----------
asn1crypto 1.2.0
astroid 2.3.3
autopep8 1.5.1
certifi 2020.4.5.1
cffi 1.13.0
chardet 3.0.4
conda 4.8.3
conda-package-handling 1.6.0
cryptography 2.8
idna 2.8
isort 4.3.21
lazy-object-proxy 1.4.3
mccabe 0.6.1
pathtools 0.1.2
pip 20.0.2
pycodestyle 2.5.0
pycosat 0.6.3
pycparser 2.19
pylint 2.4.4
pyOpenSSL 19.0.0
PySocks 1.7.1
requests 2.22.0
ruamel-yaml 0.15.46
setuptools 41.4.0
six 1.12.0
tqdm 4.36.1
treetaggerwrapper 2.3
typed-ast 1.4.1
urllib3 1.24.2
watchdog 0.10.2
wheel 0.33.6
wrapt 1.11.2
Conda vs. pip
Conda ist ähnlich wie pip auch ein Paketmanager, kann also zum Beispiel mit
conda installPakete nachinstallieren. Wir haben Conda benutzt um ein Basissystem mit Python 3.7 und pip zu installieren, im Folgenden werden wir aber ausschließlich pip benutzen. Welchen der Paketmanager Sie für Ihre eigenen Projekte nutzen wollen ist Geschmacksfrage. Conda kann teilweise mit Paketen, die Nicht-Python-Abhängigkeiten (wie zum Beispiel Compiler oder Bibliotheken für maschinelles Lernen) nutzen besser verwalten, es ist mehr vergleichbar mit einem Paketmanager für Betriebsysteme. Im Gegensatz dazu, ist der Fokus von pip auf reinen Python-Abhängigkeiten. Der Python Package Index (PyPI) als zentrale Anlaufstelle für pip-Pakete stellt enorm viele Pakete bereit und es ist auch einfach möglich, selbst Python-Pakete auf PyPI zu veröffentlichen. Neuere Versionen von Conda sind in der Lage, beim Paketmanagement mit pip zu kooperieren,conda listwird zum Beispiel auch die mit pip installiereten Pakete aufzeigen.
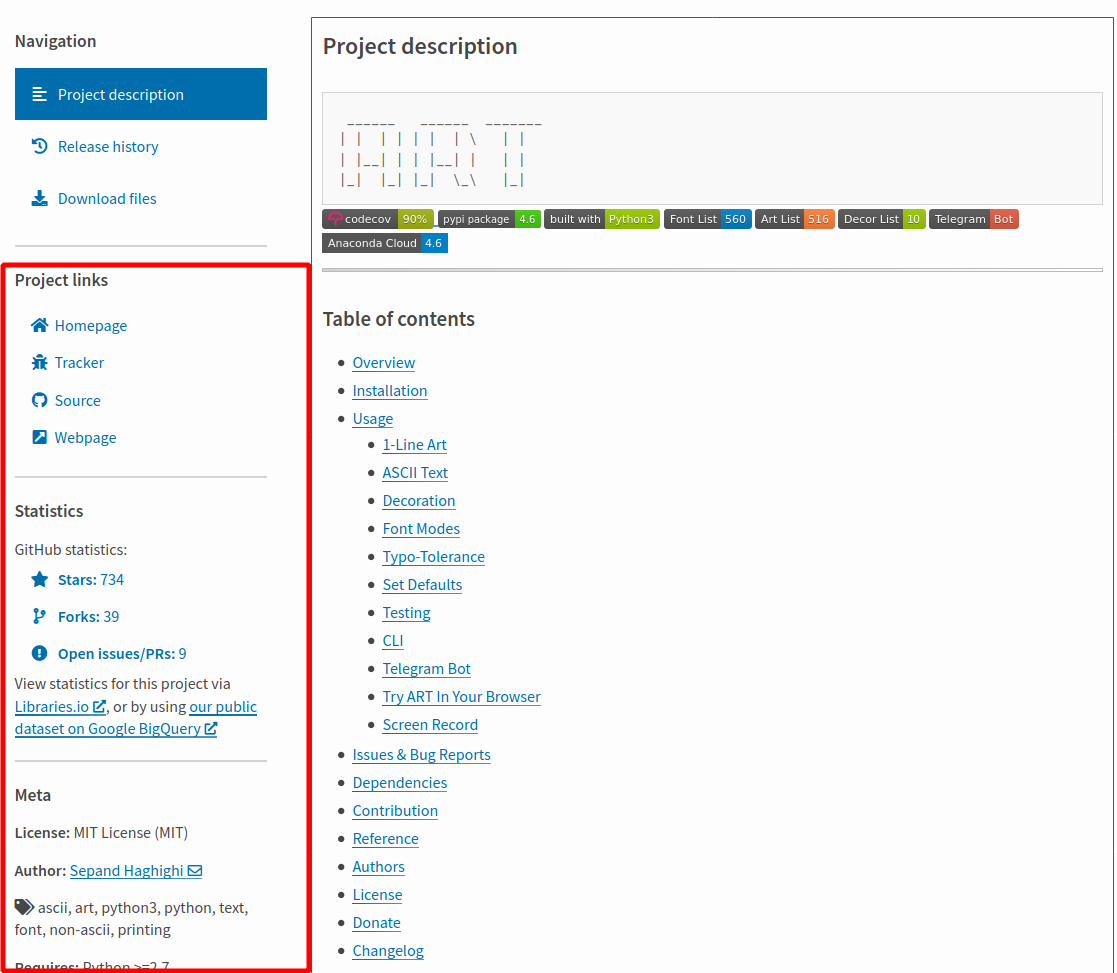
Wir wollen nun auf PyPI ein Paket finden, mit dem wir sogenanntes ASCII Art generieren wollen.
Dazu benutzen wir auf https://pypi.org/ die Suche, z.B. nach „ascii art“.
Nach etwas stöbern in der Trefferliste, finden wir zum Beispiel das Paket art:
https://pypi.org/project/art/
Sie sollten sich immer genaue die Metadaten zum Paket, wie z.B. die Lizenz und Autorenschaft anschauen.
Mit dem Befehl
pip install art
in der System-Kommandozeile kann das Paket installiert werden.
Danach ist es über import art für eigene Python-Skripte oder auf der interaktiven Python-Konsole verfügbar:
import art
print(art.text2art("Python"))
____ _ _
| _ \ _ _ | |_ | |__ ___ _ __
| |_) || | | || __|| '_ \ / _ \ | '_ \
| __/ | |_| || |_ | | | || (_) || | | |
|_| \__, | \__||_| |_| \___/ |_| |_|
|___/
Kernpunkte
Mit Funktionen können Teile von Programmen ausgegliedert und nachgenutzt werden.
Eigene Module können in Python-Dateien abgespeichert und mit
importin anderen Python-Skripten nachgenutzt werden.Mit
pipkönnen neue Pakete, die Module enthalten, installiert werden.
Levenshtein-Distanz
Overview
Teaching: 15 min
Exercises: 90 minQuestions
Wie kann man die Levenshtein-Distanz selbst in Python berechnen?
Objectives
Anwenden vom Wissen zur Organisation von Quelltext
Implementierung eines gegebenen Algorithmus
Nutzung von NLTK zur Berechnung der Levenshtein-Distanz
NLTK ist eine Python-Bibliothek zur Umsetzung vieler NLP-Standard-Aufgaben und auch über pip verfügbar. Mit aktivierter Conda-Umgebung kann es kann einfach im System-Terminal mit
pip install nltk
installiert werden.
Die Bibliothek ist in Untermodulen organisiert.
Für Metriken wie die Levenshtein-Distanz, gibt es das Untermodul nltk.distance
(Dokumentation)
NLTK mit
import nltk
in einem Python-Skript importiert werden.
Paketnamen und NLTK
Paketnamen in NLTK sind nicht unbedingt Modulnamen. So gibt es zwar das Paket
nltk.metrics, aber nach dem Importieren ist der Name des Modulsnltk.distance. Das liegt an der etwas verwirrenden internen Modulstruktur von NLTK. Zudem gibt es ein anderes Modul mit dem Namenmetrics, aber aus demnltk.translatePaket und für Konflikte in den Modulnamen sorgt. Nutzen Sie einfachnltk.distanceals Modulenamen, auch wenn die Dokumentation vonnltk.metrics.distancespricht.
Die Levenshtein-Distanz ist als Funktion mit der Signatur edit_distance(s1, s2) implementiert.
nltk.distance.edit_distance("Geisterbahn", "Achterbahn")
4
Eigene Implementierung der Levenshtein-Distanz
Wie kann man nun selbst eine Funktion schreiben, die die Levenshtein-Distanz berechnet?
Die Beschreibung des Algorithmus ist folgende: Man berechnet die Distanz
- vom längeren Wort zum kürzeren
- von jedem Buchstaben aus
- und wählt dann das Minimum
Das allein gibt uns noch keine gute Beschreibung zur eigentlichen Umsetzung, deswegen versuchen wir, das Problem in kleinere Teilprobleme aufzuteilen, die einfacher zu fassen zu sind. Diese Teillösungen kombinieren wir dann zur ganzen Lösung. Es ist zwar notwendig, das Problem in Teilprobleme aufzuteilen, aber dadurch wird es auch schwieriger die Motivation der Teilprobleme und Lösungsansätze zu verstehen. Wenn Sie an einer Stelle nicht weiterkommen, schauen Sie sich die Lösung an und versuchen Sie diese zu verstehen. Am Ende der Übung wird es hoffentlich klarer, wie die einzelnen Teilprobleme zusammenhängen.
„vom längeren Wort zum kürzeren“
Übung
Überlegen Sie, was der Punkt „vom längeren Wort zum kürzeren“ für die eigentliche Berechnung bedeutet? Was sind die einfachsten Fälle für diesen Teil der Berechnung? Schreiben Sie eine Funktion für diese einfachen Fälle. Die Funktion soll überprüfen ob der Fall zutrifft und die Levenshtein-Distanz in diesem Fall zurückgeben.
Lösung
Der einfachste Fall ist, dass einer der beiden Strings leer ist. In diesem Fall ist die Länge des anderen Strings die Anzahl der Edit-Schritte (hier Anzahl der zu hinzuzufügenden Zeichen) und damit die Levenshtein-Distanz.
def levenshtein_distance_add(a, b): # Basisfall: leere Zeichenketten bei einem der beiden Strings # --> man muss die Zeichen des anderen Strings hinzufügen if len(a) == 0: return len(b) if len(b) == 0: return len(a) # Basisfall ist nicht eingetreten return None
„von jedem Buchstaben aus“
Übung
Was bedeutet der Punkt „von jedem Buchstaben aus“ für die eigentliche Berechnung? Was sind die einfachsten Fälle für diesen Teil der Berechnung? Wie viele Zeichen müssen minimal zwischen beiden Strings verglichen werden und wenn ja welche(s)? Schreiben Sie eine Funktion für diesen einfachen Fall der die Levenshtein-Distanz in diesem Fall zurückgibt.
Lösung
In dieser Funktion wollen wir immer nur ein Zeichen zwischen zwei Strings vergleichen. Es bietet sich an, das letzte Zeichen der Strings dafür zu nehmen. Wenn die letzten Zeichen der Strings gleich sind, ist keine Änderung notwendig und die Distanz ist 0, ansonsten ist sie 1 (da ja nur genau ein Zeichen geändert werden muss).
def levenshtein_distance_modify(a, b): if a[-1] == b[-1]: # Keine Änderung des letzten Zeichens notwendig return 0 else: # Änderung des letzten Zeichens notwendig return 1
„und wählt dann das Minimum“
Frage(n)
Was bedeutet der Punkt „und wählt dann das Minimum“ für die eigentliche Berechnung? Minimum von was?
Lösung
Wir können bereits die Levenshtein-Distanz für bestimmte Basisfälle berechnen. Wenn wir die Levenshtein-Distanz für Teilstrings hätten, bei den wir bei einem der Strings ein Zeichen entfernen oder eines ändern, könnten wir die Levenshtein-Distanz für diese neuen Teilstrings berechnen. Die Levenshtein-Distanz plus die „Kosten“ für das Entfernen oder ändern des Zeichens ergibt die Distanz für beide Gesamtstrings. Wir können die Variante (also ob löschen von Zeichen oder Ändern), die am wenigsten Kosten verursacht auswählen und als Wert zurückgeben.
Rekursion
Für die Lösung der dieser Aufgabe müssen Sie sich mit rekursiven Funktionsaufrufen beschäftigen. Rekursion beim Programmieren ist ein schwieriges Thema, das gerade am Anfang schwer zu greifen ist. Grundsätzlich können Funktionen andere Funktionen aufrufen und bilden dabei eine Art Ausführungsbaum.
Wenn man z.B. im folgenden Beispiel die Funktion
mainaufruft, kann man anhand der Ausgabe die einzelnen Ausführungsschritte nachvollziehen.def a(): print("a") def b(): print("b") a() def main(): print("main") a() b() main()main a b aErst wird
main()aufgerufen, dass ersta()aufruft, dann ruftmain()b()auf, was wieder selbst die Funktiona()aufruft.main / \ a b \ aRekursive Funktionen rufen sich selbst auf, was zu potentiell unendlich tiefen Ausführungsbäumen führen kann. Es ist daher wichtig, dass eine rekursive Funktion immer eine Art Abbruchbedingung hat, bei der sie sich nicht weiter rekursiv selbst aufruft.
Übung
Schreiben Sie eine Funktion, die die Fälle vorher kombiniert und immer eine Levenshtein-Distanz für zwei gegebene Strings ausgibt. Diese Funktion soll sich rekursiv für immer kleiner werdende Teilzeichenketten selbst aufrufen und die das Minimum der Levenshtein-Distanz für diese Teilzeichenketten auswählen. Im Basisfall, dass einer der beiden String leer ist, wird die Rekursion abgebrochen.
Lösung
def levenshtein_distance(a, b): add_cost = levenshtein_distance_add(a, b) if add_cost != None: # Basisfall traf zu, der rekursive Aufruf wird abgebrochen return add_cost cost = levenshtein_distance_modify(a,b) # Gebe das Mimimum der Einzelfälle zurück: # - entferne letztes Zeichen von a # - entferne letztes Zeichen von b # - entferne letztes Zeichen von beiden Strings return min( levenshtein_distance(a[:-1], b) + 1, levenshtein_distance(a, b[:-1]) + 1, levenshtein_distance(a[:-1], b[:-1]) + cost )
Vollständige Implementierung (mit Rekursion)
Lösung
def levenshtein_distance_add(a, b): # Basisfall: leere Zeichenketten bei einem der beiden Strings # --> man muss die Zeichen des anderen Strings hinzufügen if len(a) == 0: return len(b) if len(b) == 0: return len(a) # Basisfall ist nicht eingetreten return None def levenshtein_distance_modify(a, b): if a[-1] == b[-1]: # Keine Änderung des letzten Zeichens notwendig return 0 else: # Änderung des letzten Zeichens notwendig return 1 def levenshtein_distance(a, b): cost = 0 add_cost = levenshtein_distance_add(a, b) if add_cost != None: # Basisfall traf zu, der rekursive Aufruf wird abgebrochen return add_cost cost = levenshtein_distance_modify(a,b) # Gebe das Mimimum der Einzelfälle zurück: # - entferne letztes Zeichen von a # - entferne letztes Zeichen von b # - entferne letztes Zeichen von beiden Strings return min( levenshtein_distance(a[:-1], b) + 1, levenshtein_distance(a, b[:-1]) + 1, levenshtein_distance(a[:-1], b[:-1]) + cost )
Optimierung von rekursiven Funktionen(n)
Sie werden bemerken, dass die Funktion
levenshtein_distanceviel Zeit für die Berechnung der Distanz für längere Strings braucht. Beim rekursiven Aufruf kann es vorkommen, dass verschiedene Rekursionsschritte die Funktion mit den gleichen Parametern aufrufen, aber jeweils neu berechnen. Das ist sehr aufwendig, kann aber vereinfacht werden, in dem man Python anweist, Aufrufe vonlevenshtein_distancemit den gleichen Parametern zu cachen. Beim Caching wird die Funktion nur beim ersten Aufruf mit den gleichen Argumentwerten wirklich ausgeführt. Der Python-Interpreter merkt sich dann den Rückgabewert für diese Funktion und Argumente. Wenn wir die Funktion noch einmal mit den gleichen Argumenten aufgerufen, wird dieser Wert direkt zurückgeben. Um den Cache für den Funktionsaufruf zu aktivieren, müssen Sie nur@lru_cache(maxsize=128)(Dokumentation) als sogenannten „decorator“ vor die Funktionsdefinition schreiben. Damit werden die 128 zuletzt genutzten Rückgabewerte gecached („lru“ steht „last recently used“).from functools import lru_cache @lru_cache(maxsize=128) def levenshtein_distance(a, b): cost = 0 # [...]
Kernpunkte
Man sollte versuchen größere Aufgaben in kleinere, einfache zu handhabene Teilaufgaben aufzuteilen
Funktionen sind nützlich, um diese kleineren Teilaufgaben abzubilden
Texte in NLTK
Overview
Teaching: 130 min
Exercises: 0 minQuestions
Wie werden Text in NLTK dargestellt?
Wie kann man auf diese Texte zugreifen?
Was kann man mit den Texten an einfachen statistischen Auswertungen durchführen?
Objectives
Laden der vorgefertigten NLTK Buch Beispieltexte
Einfache Auswertungen auf diesen Texten
Das NLTK besteht aus verschiedenen Modulen für
verschiedene Aufgaben, z.B. nltk.corpora, nltk.parse oder nltk.stem.
Eine Übersicht der Module finden Sie z.B. im Vorwort des NLTK-Buchs.
Viele Beispiele sind auch aus dem NLTK-Buch übernommen, und es lohnt sich, als Nachbereitung die Kapitel 1 bis 3 durchzulesen.
Download von NLTK-Ressourcen
Es gibt zusätzlich eine Datenkollektion (Korpora und anderes), die für das NLTK-Buch zusammengestellt wurde. Um diese herunterzuladen, öffnen Sie eine Python-Konsole und führen Sie folgenden Code aus:
import nltk
nltk.download()
Es erscheint eine graphische Oberfläche, auf der Sie die „Collection“ „book“ auswählen müssen und dann über die Schaltfläche „Download“ herunterladen können. Danach können Sie die verschiedenen Korpora in Python importieren, in dem Sie
from nltk.book import *
ausführen.
*** Introductory Examples for the NLTK Book ***
Loading text1, ..., text9 and sent1, ..., sent9
Type the name of the text or sentence to view it.
Type: 'texts()' or 'sents()' to list the materials.
text1: Moby Dick by Herman Melville 1851
text2: Sense and Sensibility by Jane Austen 1811
text3: The Book of Genesis
text4: Inaugural Address Corpus
text5: Chat Corpus
text6: Monty Python and the Holy Grail
text7: Wall Street Journal
text8: Personals Corpus
text9: The Man Who Was Thursday by G . K . Chesterton 1908
Nach dem Import sind die verschiedenen Korpora als Variablen mit dem Namen text1, text2 etc. vorhanden.
Frage(n)
Welchen Typ haben diese Variablen?
Lösung
Wir können den Typ einfach mit
type(text1)überprüfen. Die Variablen mit den Texten haben nicht den Typ String, sondern den NLTK-eigenen Typnltk.text.Text. Welche Methoden wir auf diesen Typ nutzen können, schauen wir uns im Rest des Tutorials an.
Texte als Sequenzen von Wörtern
Wir haben bereits Zeichenketten als Sequenzen von Zeichen betrachtet.
In Korpora wird typischerweise bereits ein weiterer Vorverarbeitungsschritt vorausgesetzt, nämlich
dass die Texte in Token unterteilt sind.
Token sind typischerweise Wörter und Punktuationen.
Ein Text ist dann eine Sequenz von Token und kann wie eine Liste interpretiert werden.
Obwohl der Typ von NLTK-Texten nltk.text.Text ist, kann man die Variablen wie eine Liste von Zeichenketten nutzen.
Man kann sich zum Beispiel die ersten 10 Wörter eines Textes über die Listen-Indexierung ([n:m]) ausgeben lassen.
text4[0:10]
['Fellow', '-', 'Citizens', 'of', 'the', 'Senate', 'and', 'of', 'the', 'House']
Die Ausgabe ist wiederum von Typ list.
type(text4[0:10])
<class 'list'>
Suche in Texten
Wenn man nun nach „einen Wort in einem Text“ suchen möchte, kann das mehrere Dinge heißen:
- Ist ein Wort überhaupt in einem Text enthalten?
- An welcher Stelle ist ein Wort in einem Text enthalten?
- Wie oft ist ein Wort in einem Text enthalten?
Prüfen ob Element enthalten ist über den in Ausdruck
Mit dem Ausdruck wert in liste kann überprüft werden, ob ein Element in einer Liste vorhanden ist.
nachspeisen = ["Obst", "Quark", "Eis"]
if "Obst" in nachspeisen:
print("Heute mal gesund.")
else:
print("Esst mehr Obst!")
Da NLTK-Texte Listen von Zeichenketten sind, kann man mit in auch überprüfen, ob ein Wort im Text vorhanden ist.
Übung
Überprüfen Sie, ob irgendeiner Antrittsrede eines US-Präsidenten das Wort „fruit“ vorkommt.
Lösung
Ja, denn
"fruit" in text4ergibt
True.
Stelle finden, an dem ein Wort im Text vorkommt
Mit der Funktion text.index(wert) kann das erste Vorkommen eines Wortes im Text als Index der Liste gefunden werten
i = text4.index("fruit")
print(i)
print(text4[i-1], text4[i], text4[i+1])
13694
the fruit of
Zählen wie oft ein Wort im Text enthalten ist
Mit der Funktion text.count(wert) kann gezählt werden, wie oft ein Wort im Text vorkommt.
text4.count("fruit")
2
Komplexere Bedigungen abfragen
Man kann für jedes Wort des Textes eine Bedingung überprüfen, in dem man mit einer for-Schleife über die Wörter des Textes iteriert und für jedes Wort eine if-Abfrage ausführt.
from nltk.book import text4
for word in text4:
if word.startswith("fr"):
print(word)
*** Introductory Examples for the NLTK Book ***
Loading text1, ..., text9 and sent1, ..., sent9
Type the name of the text or sentence to view it.
Type: 'texts()' or 'sents()' to list the materials.
text1: Moby Dick by Herman Melville 1851
text2: Sense and Sensibility by Jane Austen 1811
text3: The Book of Genesis
text4: Inaugural Address Corpus
text5: Chat Corpus
text6: Monty Python and the Holy Grail
text7: Wall Street Journal
text8: Personals Corpus
text9: The Man Who Was Thursday by G . K . Chesterton 1908
from
frequent
from
from
from
free
from
free
from
freemen
from
from
from
frankly
from
from
frontier
from
friends
from
from
fresh
from
from
from
free
[...]
Eleganter (und schneller) ist aber die Verwendung einer sogenannten „list comprehension“, einer aussagelogischen Abfrage:
[word for word in text4 if word.startswith("fr")]
['from', 'frequent', 'from', 'from', 'from', 'free', 'from', 'free', 'from', 'freemen', 'from', 'from', 'from', 'frankly', 'from', 'from', 'frontier', 'from', 'friends', 'from', 'from', 'fresh', 'from', 'from', 'from', 'free', 'fraud', 'fruits', 'from', 'free', 'from', 'friendly', 'friendly', 'friendship', 'friendship', 'fruitful', 'from', 'freely', 'from', 'free', 'free', 'from', 'from', 'from', 'from', 'frugal', 'from', 'free', 'from', 'friendship', 'from', 'freedom', 'freedom', 'freedom', 'from', 'from', 'freedom', 'from', 'from', 'friendship', 'from', 'from', 'frontiers', 'from', 'friendly', 'free', 'from', 'from', 'friends', 'from', 'freedom', 'freedom', 'from', 'friend', 'from', 'from', 'from', 'from', 'friendship', 'from', 'from', 'free', 'from', 'fruits', 'from', 'from', 'friendly', 'free', 'from', 'freedom', 'friendly', 'from', 'from', 'from', 'from', 'from', 'from', 'free', 'from', 'from', 'from', 'free', 'from', 'fraught', 'from', 'from', 'from', 'from', 'friendship', 'from', 'from', 'from', 'frontiers', 'from', 'from', 'free', 'from', 'from', 'fruit', 'from', 'friendly', 'free', 'from', 'from', 'from', 'from', 'frontiers', 'frontiers', 'from', 'from', 'front', 'from', 'from', 'from', 'from', 'from', 'from', 'from', 'from', 'friendship', 'free', 'from', 'from', 'from', 'from', 'from', 'from', 'from', 'free', 'from', 'from', 'from',
[...]
Der grundsätzliche Aufbau des Ausdrucks ist
[ausdruck for element in liste if bedingung]
Für jedes item in der liste wird der ausdruck ausgeführt, wenn die bedingung wahr ist.
Das Ergebnis ist eine Liste aller Werte, die durch den Ausdruck generiert werden.
fr_woerter = [word for word in text4 if word.startswith("fr")]
print(fr_woerter)
print(type(fr_woerter))
[...]
'from', 'freedom', 'free', 'freedom', 'freedom', 'freedom', 'free', 'freedom', 'friendship', 'free', 'freedom', 'free', 'freedom', 'freedom', 'free', 'fragile', 'freedom', 'freedom', 'free', 'freedom', 'from', 'freedom', 'freedom', 'from', 'freedom', 'freedom', 'freedom', 'freedom', 'free', 'freedom', 'freedom', 'freedom', 'from', 'free', 'freedom', 'free', 'freedom', 'from', 'friend', 'from', 'friends', 'from', 'from', 'friend', 'freedom', 'freedom', 'from', 'free', 'free', 'from', 'freedoms', 'from', 'free', 'freedom', 'free', 'friendsâ', 'from', 'from', 'freedom', 'freedom', 'freedom', 'from', 'from', 'from', 'from', 'from', 'freedom', 'from', 'from', 'from', 'from', 'from', 'friendship', 'from', 'free', 'from', 'freedoms', 'from', 'from']
<class 'list'>
Ein Aufruf von print innerhalb der „list comprehension“ funktioniert daher in der interaktiven Konsole,
die immer den Rückgabewert ausgibt, nur bedingt.
[print(word) for word in text4 if word.startswith("friends")]
friends
friendship
friendship
friendship
friendship
friends
friendship
friendship
friendship
friends
friendship
friendship
friendship
friends
friends
friendship
friendship
friendship
friends
friends
friends
friendship
friends
friends
friendship
friendship
friends
friends
friends
friends
friends
friends
friends
friendship
friendship
friends
friends
friendships
friends
friendship
friends
friends
friends
friends
friends
friends
friendship
friends
friends
friends
friends
friends
friendships
friends
friends
friendship
friends
friendsâ
friendship
Out[6]:
[None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None]
„List comprehension“ Ausdrücke sind also am besten dazu geeignet, Listen zu generieren.
Man kann für die Bedingung auch reguläre Ausdrücke verwenden, wenn man das re Modul importiert und
die re.search(pattern, word) Funktion verwendet.
Z.B. kann man nach allen Wörtern suchen, die mit „fruit“ anfangen, aber noch mehre Zeichen enthalten können:
import re
[w for w in text4 if re.search("fruit.*", w)]
fruits
fruitful
fruits
fruit
fruits
fruitful
fruitful
fruits
[...]
Oder z.B. die Suche nach allen Wörtern, die mit „end“ oder „begin“ enden:
[w for w in text4 if re.search(".+(end|begin)$", w)]
recommend
depend
depend
comprehend
extend
extend
contend
tend
friend
contend
depend
depend
depend
extend
depend
[...]
Mengen
Neben Listen gibt es in Python auch Mengen, oder sogenannte Sets.
Eine Menge enthält keine Duplikate, kann aber aus Listen mit der set(...) Funktion erstellt werden.
Außerdem ist die Reihenfolge einer Menge nicht festgelegt.
original = ["Eis", "Obst", "Quark", "Eis"]
nachspeisen = set(original)
print(len(original), len(nachspeisen))
4 3
Im Vergleich zur originalen Liste wurde in der Menge das doppelte "Eis" entfernt und daher ist die Länge nur 3 anstatt 4.
print(nachspeisen)
{'Eis', 'Obst', 'Quark'}
Da Mengen keine Reihenfolge haben, werden neue Element mit der Funktion add(v) hinzugefügt.
Mit remove(v) können sie entfernt werden.
l = set() # leere Menge
l.add(1) # wir fügen der Menge Elemente hinzu
l.add("Piano")
l.add(1.42)
l.add(1.43)
l.add(1.42)
print(l)
{1, 1.43, 1.42, 'Piano'}
l.remove("Piano")
print(l)
{1, 1.43, 1.42}
Die Funktionen in funktioniert auch auf Mengen:
1 in l
True
Ebenso gibt es die Funktion not in um zu überprüfen ob etwas nicht in der Menge enthalten ist:
13 not in l
True
Geschwindigkeit von Sets .vs Listen
Die Überprüfung, ob ein Wert Teil eines Sets ist kann deutlich schneller geschehen als in einer Liste. Während in einer Liste wirklich jedes Element angeschaut werden muss, gibt es für Sets Indexstrukturen, die annähernd konstant und unabhängig von der Länge der Liste die (Nicht)-Zugehörigkeit eines Werts überprüfen können. Insbesondere bei großen Datenmengen kann es also von Vorteil sein ein Set zu nutzen, soweit es semantisch Sinn macht.
Frage(n)
Ist der Ausdruck
"1.42" in lfür die Menge{1, 1.43, 1.42}wahr?Lösung
Nein, denn
"1.42"ist ein String und das Element in der Menge ist eine Ganzkommazahl. Elemente müssen vom Typ gleich sein um verglichen werden zu können. Mit Hilfe der Typumwandlungsfunktion (str(v),int(v),float(v), etc.) können solche Umwandlungen vorgenommen werden. Für einige Typen geschieht die Umwandlung automatisch, so ist z.B.1.0 in lwahr, da ein Float zu einem Integer automatisch umgewandelt wird.
Wenn man Texte mit einer komplexen Bedingung durchsucht, kann man die daraus entstandene Liste zu einer Menge machen, um jeder Variante nur noch einmal vorkommen zu lassen:
import re
from nltk.book import text4
words = [w for w in text4 if re.search(".+(end|begin)$", w)]
words = set(words)
print(words)
{'comprehend', 'lend', 'recommend', 'tend', 'dividend', 'Godsend', 'attend', 'send', 'spend', 'rend', 'trend', 'friend', 'Reverend', 'apprehend', 'extend', 'contend', 'reverend', 'legend', 'intend', 'transcend', 'blend', 'depend', 'defend', 'superintend', 'pretend', 'bend'}
Konkordanz auf NLTK-Texten
Das NLTK hat eine eigene Konkordanzfunktion:
text4.concordance("fruit")
Displaying 2 of 2 matches:
as we do all the raw materials , the fruit of our own soil and industry , we ou
ce will grow greater and bear richer fruit with the coming years . No doubt thi
Damit können die gefunden Stellen gemeinsam mit ihren Kontext angezeigt werden. In diesem Fall ist der Kontext durch die Wörter/Zeichen links und rechts vom Treffer gegeben.
Die Konkordanzfunktion arbeitet auf tokenisiertem Text - sie kann deshalb nicht über mehrere Wörter suchen:
text4.concordance("fruit of")
no matches
liefert keine Matches, weil es das Token „fruit of“ nicht gibt!
Die Konkordanzfunktion funktioniert nur auf der Datenstruktur Text, die vom NLTK vorgegeben wird.
Übung
Wie können wir uns den Kontext für das Ergebnis einer Mustersuche ausgeben lassen?
Lösung
words = set([w for w in text4 if re.search(".+(end|begin)$", w)]) for w in words: text4.concordance(w)
Vorkommen eines Worts im Text
Wenn man eine Übersicht haben möchte, an welchen Stellen ein Wort im Text vorkommt, kann man einen sogenannten „dispersion plot“ nutzen:
text4.dispersion_plot(["citizens", "democracy", "freedom", "duties", "America"])
Um die Methode zu nutzen, muss das Paket “matplotlib” installiert sein.
pip install matplotlib
Einfache statistische Auswertungen
Wortfrequenzen
Um die Frequenz der Wörter für ein Korpus berechnen, kann man mit der Funktion FreqDist(text) ein neues Objekt anlegen, dass die Vorkommen zählt und die Möglichkeit gibt, auf verschiedene Aspekte der Frequenzanalyse zuzugreifen.
fdist1 = FreqDist(text1)
print(fdist1)
<FreqDist with 19317 samples and 260819 outcomes>
Mit der Methode .most_common(n) kann man sich jetzt die n häufigsten Wörter ausgeben lassen.
fdist1.most_common(50)
[(',', 18713), ('the', 13721), ('.', 6862), ('of', 6536), ('and', 6024), ('a', 4569), ('to', 4542), (';', 4072), ('in', 3916), ('that', 2982), ("'", 2684), ('-', 2552), ('his',2459), ('it', 2209), ('I', 2124), ('s', 1739), ('is', 1695), ('he', 1661), ('with', 1659), ('was', 1632), ('as', 1620), ('"', 1478), ('all', 1462), ('for', 1414), ('this', 1280), ('!', 1269), ('at', 1231), ('by', 1137), ('but', 1113), ('not', 1103), ('--', 1070), ('him', 1058), ('from', 1052), ('be', 1030), ('on', 1005), ('so', 918), ('whale', 906), ('one', 889), ('you', 841), ('had', 767), ('have', 760), ('there', 715), ('But', 705), ('or', 697), ('were', 680), ('now', 646), ('which', 640), ('?', 637), ('me', 627), ('like',624)]
Über einen Indexzugriff kann man auch die Häufigkeit eines gegebenen Wortes ausgeben:
fdist1['whale']
906
Man kann die Frequenzen auch wieder plotten lassen:
print(len(text1))
fdist1.plot(50)
260819
Wenn man die Häufigkeiten der häufigsten 50 Wörter aufaddiert kann man sehen, dass diese fast die Hälfte des Gesamttextes umfassen.
print(len(text1))
fdist1.plot(50, cumulative=True)
260819
Durchschnittliche Wortlänge
Man kann mit FreqDist() auch andere Dinge berechnen, wie z.B. die Verteilung der Wortlänge eines Textes.
Dazu erstellen wir zuerst ein neue List, in der für jedes Wort des Textes die Länge eingetragen ist.
Übung
Erstellen Sie eine Liste mit den Wortlängen des Textes
text1!Lösung
l = [len(w) for w in text1] print(l)[1, 4, 4, 2, 6, 8, 4, 1, 9, 1, 1, 8, 2, 1, 4, 11, ...]
Jetzt können wir die Frequenz der verschiedenen Wortlängen direkt berechnen:
ldist = FreqDist(l)
print(ldist.most_common(10))
ldist.plot()
[(3, 50223), (1, 47933), (4, 42345), (2, 38513), (5, 26597), (6, 17111), (7, 14399), (8, 9966), (9, 6428), (10, 3528)]
Wir können auch direkt die häufigste Wortlänge mit der Methode .max() berechnen lassen:
ldist.max()
3
Kollokation
Kollokationen sind Sequenzen von ungewöhnlich häufig zusammen auftretenden Wörtern. Sequenzen von Wörtern, bei denen jedes einzelne Wort bereits häufig auftritt sind keine auffälligen Kollokationen, z.B. sind „the“ und „wine“ in einem Text vielleicht einzeln schon sehr häufig, deswegen ist klar, dass „the wine“ ebenfalls häufig auftritt und keine Kollokation. Dagegen ist „red wine“ eine, da die Sequenz der beiden Wörter häufiger auftritt als die einzelne Frequenz der beiden Wörter dies erwarten lassen würde.
Ein Beispiel für die Frequenz von „the“, „wine“ und „red“ in einem der Texte:
print(fdist1["the"])
print(fdist1["wine"])
print(fdist1["red"])
13721
12
36
Nun ist die Frage, wie man die Häufigkeit von „red wine“ finden kann.
Als erstes muss man eine Liste von sogenannten Bigrammen erstellen, also alle
Paare von Wörtern die jeweils als Sequenz im Text vorkommen.
Bigramme können mit Methode bigrams(text) erstellt werden.
for b in bigrams(text1):
print(b)
('Nantucket', 'commanders')
('commanders', ';')
(';', 'that')
('that', 'from')
('from', 'the')
('the', 'simple')
('simple', 'observation')
('observation', 'of')
('of', 'a')
[...]
Die einzelnen Bigramme sind vom Typ Tupel, den wir bisher noch nicht kennengelernt haben. Tupel sind ähnlich wie Listen, allerdings ist die Anzahl der Element fest und es können nicht neue Element angehängt oder bestehende gelöscht werden. Ein Tupel-Wert kann in Python mit Hilfe von Klammern angelegt werden.
t = ("red", "wine")
type(t)
print(t)
print(t[0])
print(t[1])
<class 'tuple'>
('red', 'wine')
'red'
'wine'
Listen von Bigrammen können nun ähnlich wie Listen von Wörtern behandelt werden, indem z.B. Frequenzlisten davon erstellt und ausgewertet werden.
bf = FreqDist(bigrams(text1))
print(bf.most_common(10))
print(bf[("red", "wine")])
print(bf[("the", "wine")])
[((',', 'and'), 2607), (('of', 'the'), 1847), (("'", 's'), 1737), (('in', 'the'), 1120), ((',', 'the'), 908), ((';', 'and'), 853), (('to', 'the'), 712), (('.', 'But'), 596), ((',', 'that'), 584), (('.', '"'), 557)]
1
0
Während „the“ häufiger vorkommt als „red“, gibt es kein einziges Bigramm „the wine“ in diesem Text, während „red wine“ einmal vorkommt. Damit ist „red wine“ eine Kollokation.
Nun kann man für einen Text direct mit der Methode .collocation_list() häufige Bigramme finden.
text4.collocation_list()
United States; fellow citizens; four years; years ago; Federal
Government; General Government; American people; Vice President; Old
World; Almighty God; Fellow citizens; Chief Magistrate; Chief Justice;
God bless; every citizen; Indian tribes; public debt; one another;
foreign nations; political parties
text8.collocation_list()
would like; medium build; social drinker; quiet nights; non smoker;
long term; age open; Would like; easy going; financially secure; fun
times; similar interests; Age open; weekends away; poss rship; well
presented; never married; single mum; permanent relationship; slim
build
Kernpunkte
Texte sind Sequenzen von Token und können wir Listen von Strings behandelt werden
Es ist in NLTK direkt möglich, Frequenzanalysen, Kollokationen und andere einfache statistische Auswertungen auf Texten durchzuführen.
Dateien lesen und schreiben
Overview
Teaching: 10 min
Exercises: 30 minQuestions
Wie können Dateien durch Python verarbeitet werden?
Objectives
Ein- und Auslesen von Dateien
Daten von der Festplatte laden und wieder speichern
Wenn wir unsere linguistische Forschung mit technischen Mitteln unterstützen wollen, kommen wir nicht umhin gespeicherte Sprachdaten zu laden und berechnete Auswertungen und/oder Aufbereitungen zu speichern. Unsere Berechnungen und Variablenbelegungen zur Laufzeit des Programmes sind im Hauptspeicher des Computers gespeichert. Dieser ist flüchtig. Persitenz bietet nur die Festplatte.
Lesen
Also, beginnen wir mit dem einfachen Laden. Hierfür benötigen wir open (schauen Sie für die Beschreibung der verwendeten Funktionen auch in die Python-Hilfe):
f1 = open('demofile.txt', 'r')
content1 = f1.read()
# ...
f2 = open('demofile.txt', 'r')
content2 = f2.readlines()
# ...
Frage(n)
- Was passiert in jeder Zeile des Programmes?
- Welchen Typ hat
fund welchen Typ hatcontent1bzw.content2?- Was fehlt noch? Warum ist das wichtig?
- Was ist der Unterschied zwischen
readundreadlines?Lösung
Die Funktion
openöffnet die Datei im Lesemodus ("r"als Wert für den Modus-Parameter) und liest dann den Inhalt mit den Methodenread()bzw.readlines()in Variablen.read()liest die gesamte Datei als einen String und liefert einen Wert vom Typstrzurück.readlines()liest die Datei zeilenweise und liefert eine Liste mit Strings zurück. Es fehlt noch das Schließen der Dateien mit der Methodeclose().f1.close()Das Schließen von Datein ist notwendig, wenn die gleiche Datei von mehreren Programmen oder Programmteilen genutzt werden soll. Insbesondere beim mischen von Lesen und Schreiben in Dateien kann es zu Problemen kommen, wenn gleichzeitig zwei Dateivariablen offen sind.
Schreiben
Wenn wir schreiben wollen, dann geht das so:
f = open('outfile.txt', 'w')
content = 'blablabla'
f.write(content)
f.close()
Frage(n)
Existiert
outfile.txtbereits? Was kann passieren, wenn wirfnicht schließen?Lösung
Die Datei muss nicht bereits existieren, das Programm wird die Datei neu anlegen und überschreiben. Wenn
fnicht geschlossen wird, wird zwar auch die Datei angelegt, aber es kann passieren, dass der Inhalt nicht oder nicht vollständig geschrieben wird.
Einen Datei manuell in allen möglichen Code-Pfaden zu schließen kann man oft vergessen, in Python gibt es daher einen speziellen with Block, der uns das vereinfacht:
with open("outfile.txt","a") as f
f.write("hello world!\n")
# wird nach diesem Block automatisch geschlossen
Tipps und Tricks
Wenn Sie vermeiden wollen, dass Sie eine Datei überschreiben, die es schon gibt, gibt es mehrere Mittel. Zum einen können Sie einen anderen Schreibmodus verwenden:
f = open('demofile.txt', 'x')
# ...
f.close()
Der Modus x schreibt in eine neue Datei. Existiert die Datei jedoch schon, wird ein sogenannter FileExistsError ausgegeben und das Programm beendet.
Das ist jedoch nicht die eleganteste Lösung. Solche Exceptions und Errors (mehr dazu in einer späteren Sitzung) sollten vermieden werden, wo es möglich ist.
Alternativ gibt es im Modul os (Submodul path) eine Funktion exists:
from os.path import exists
print(exists('demofile.txt'))
Übung
Wir wollen alle Nomen aus einer Geschichte und in eine Datei schreiben finden. Dafür brauchen wir
- eine Liste von Wörtern, die wir aus einem String (der Geschichte) generieren
- eine Definition von Nomen - wir gehen vereinfacht davon aus, dass alle großgeschriebenen Wörter außer am Satzanfang Nomen sind
Als Geschichte nehmen wir die Zusammenfassung des Inhalts von hier: http://de.wikipedia.org/wiki/Der_Hase_und_der_Igel
Lösung
# Unsere Funktion nimmt eine Liste als Parameter def find_nouns(list_of_words): nouns = list() # Das erste Wort ist wahrscheinlich großgeschrieben, fällt aber aus unserer Definition raus for i in range(1, len(list_of_words)): current_word = list_of_words[i] if current_word[0].isupper(): # list_of_words[i-1]: Das vorherige Wort if not list_of_words[i-1].endswith("."): nouns.append(current_word) return nouns with open("hase_igel.txt") as f: story = f.read() words = story.split() nouns = find_nouns(words) with open("hase_igel_nouns.txt", "w") as result: for noun in nouns: result.write(noun + ", ")
Kernpunkte
Mit den eingebauten Funktionen
openkönnen Dateien zum Lesen und Schreiben geöffnet werden, diese müssen immer wieder geschlossen werden.
NLTK und eigene Texte
Overview
Teaching: 50 min
Exercises: 10 minQuestions
Wie kann ich meine eigenen Texte in NLTK einbinden?
Objectives
Tokensieren von Texten
Auf Argumente der Kommandozeile zugreifen
Einlesen eines eigenen Texts in NLTK
Wir wollen einen Beispieltext als Text in NLTK laden.
Dafür müssten wir als erstes eine Liste von allen Wörtern des Textes in der richtigen Reihenfolge erstellen.
Das heißt, dass wenn wir den Text zeilenweise einlesen, die Zeichenketten auftrennen müssen.
Eine einfache Methode dazu bietet die eingebaute split() Methode von Python.
Diese Methode kann aber z.B. nicht mit Punktuation umgehen.
feedback = "Die positivste Reaktion, die man in Berlin bekommen kann, ist eine fehlende Beschwerde."
feedback.split()
['Die', 'positivste', 'Reaktion,', 'die', 'man', 'in', 'Berlin', 'bekommen', 'kann,', 'ist', 'eine', 'fehlende', 'Beschwerde.']
NLTK bietet eine Funktion word_tokenize(text), die diese Aufgabe besser löst.
from nltk import word_tokenize
word_tokenize(feedback)
['Die', 'positivste', 'Reaktion', ',', 'die', 'man', 'in', 'Berlin', 'bekommen', 'kann', ',', 'ist', 'eine', 'fehlende', 'Beschwerde', '.']
Die Funktion nltk.Text erstellt aus so einer Liste von Wörtern dann einen neuen Text,
der genau so wie alle anderen Texte genutzt werden kann.
txt_de = nltk.Text(word_tokenize(feedback))
txt_de.concordance("Reaktion")
nltk.FreqDist(txt_de).plot()
Displaying 1 of 1 matches:
Die positivste Reaktion , die man in Berlin bekommen kann ,
Eine Möglichkeit, Text weiter zu verarbeiten ist das Tagging jedes Tokens nach Wortarten. Dazu erstellen wir erst einen Text aus einen einfachen englischen Beispielsatz.
txt_en = nltk.Text(word_tokenize("The most positive reaction you can get in Berlin is a missing complaint."))
txt_en.tokens
['The', 'most', 'positive', 'reaction', 'you', 'can', 'get', 'in', 'Berlin', 'is', 'a', 'missing', 'complaint', '.']
Die Funktion nltk.pos_tag(text) erlaubt jetzt das taggen eines englischen Texts:
nltk.pos_tag(txt_en)
[('The', 'DT'), ('most', 'RBS'), ('positive', 'JJ'), ('reaction', 'NN'), ('you', 'PRP'), ('can', 'MD'), ('get', 'VB'), ('in', 'IN'), ('Berlin', 'NNP'), ('is', 'VBZ'), ('a', 'DT'), ('missing', 'JJ'), ('complaint', 'NN'), ('.', '.')]
Das Ergebnis ist eine Liste von Tupeln, wobei das erste Element das Token ist und das zweite der Tag für die Wortklasse.
Das hier verwendete Tagset ist as UPenn Tagset.
Mit nltk.help.upenn_tagset(tag) kann man für eine einzelnes Tag die Beschreibung bekommen.
nltk.help.upenn_tagset('NN')
NN: noun, common, singular or mass
common-carrier cabbage knuckle-duster Casino afghan shed thermostat
investment slide humour falloff slick wind hyena override subhumanity
machinist ...
Wir werden uns später damit beschäftigen, wie diese Tagger funktionieren.
Tagsets können über den optionalen Parameter tagset ausgewählt werden, z.B. gibt es auch das „Universal POS Tagset“
nltk.pos_tag(txt_en, tagset="universal")
[('The', 'DET'), ('most', 'ADV'), ('positive', 'ADJ'), ('reaction', 'NOUN'), ('you', 'PRON'), ('can', 'VERB'), ('get', 'VERB'), ('in', 'ADP'), ('Berlin', 'NOUN'), ('is', 'VERB'), ('a', 'DET'), ('missing', 'ADJ'), ('complaint', 'NOUN'), ('.', '.')]
Um den Tagger für eine andere Sprache zu nutzen, muss das Argument lang mit angeben werden.
Als Argument muss der aus drei Buchstaben bestehende ISO 639 Code genutz werden, z.B. für Deutsch:
nltk.pos_tag(txt_de, tagset="universal", lang="deu")
NotImplementedError: Currently, NLTK pos_tag only supports English and Russian (i.e. lang='eng' or lang='rus')
In älteren Versionen von NLTK war ein sehr rudimentäre Tagger für Deutsch enthalten. Dieser wurde allerdings entfernt. Für das Beispiel hätte der alte POS-Tagger
[('Die', 'NOUN'), ('positivste', 'NOUN'), ('Reaktion', 'NOUN'), (',', '.'), ('die', 'NOUN'), ('man', 'NOUN'), ('in', 'ADP'), ('Berlin', 'NOUN'), ('bekommen', 'NOUN'), ('kann', 'VERB'), (',', '.'), ('ist', 'ADJ'), ('eine', 'NOUN'), ('fehlende', 'NOUN'), ('Beschwerde', 'NOUN'), ('.', '.')]
ausgegeben. Wir Sie sehen, war der Tagger für Deutsch ausbaufähig und seine Entfernung kein großer Verlust.
Kommandozeilenargumente
Wenn man ein Skript in der System-Konsole aufruft, kann man dem Aufruf zusätzliche per Leerzeichen getrennt Argumente übergeben.
python3 meinskript.py Argument1 NochEinArgument
Ähnlich wie bei einer Python-Funktion ist das sehr nützlich, um die gleiche Aufgabe bzw. den gleichen Algorithmus/Code auf unterschiedlichen Eingaben auszuführen. Wenn ein Skript eine Datei einliest, wäre das z.B. eine gute Möglichkeit den Dateipfad anzugeben, damit man das Skript auf verschieden Dateien ausführen kann ohne das Skript selbst fehleranfällig anpassen zu müssen.
Der Zugriff auf die Argumente erfolgt über die Liste argv aus dem Modul sys.
Dazu müssen Sie das Modul erst importieren, und können dann auf die Listen-Variable zugreifen.
Gegeben Sei das folgendes Skript in einer Datei cat.py.
import sys
print(sys.argv)
Wenn man das Skript nun mit verschiedenen Parametern auf dem System-Terminal ausführt ausführt, kann man sehen wie sich die Ausgabe verändert.
python3 cat.py
['cat.py']
python3 /home/nlp/cat.py
['/home/nlp/cat.py']
Das erste Element in der Liste sys.argv ist immer der Pfad, mit dem das Skript aufgerufen wurde, danach folgenden die anderen Argumente:
python3 cat.py Argument1 NochEinArgument
['cat.py', 'Argument1', 'NochEinArgument']
Wenn Sie z.B. das Skript cat.py abändern, können Sie den Inhalt einer beliebigen Datei, die als Argument übergeben wird, als Text ausgeben:
import sys
if len(sys.argv) < 2:
print("No file given")
else:
with open(sys.argv[1], 'r') as f:
print(f.read())
Die Abfrage, ob die Argumentliste groß genug ist fängt den Fall ab, dass kein Argument angegeben worden ist. Sie können jetzt das Skript austesten:
python3 cat.py hase_igel.txt
Bei einer zufälligen Begegnung macht sich der Hase über die schiefen Beine des Igels lustig, woraufhin ihn dieser zu einem Wettrennen herausfordert,um den Einsatz eines goldenen „Lujedor“ (Louis d’or) und einer Flasche Branntwein. Bei der späteren Durchführung des Rennens auf einem Acker läuft der Igel nur beim Start ein paar Schritte, hat aber am Ende der Ackerfurche seine ihm zum Verwechseln ähnlich sehende Frau platziert. Als der siegesgewisse Hase heranstürmt, erhebt sich die Frau des Igels und ruft ihm zu: „Ick bün al hier!“ („Ich bin schon hier!“). Dem Hasen ist die Niederlage unbegreiflich, er verlangt Revanche und führt insgesamt 73 Läufe mit stets demselben Ergebnis durch. Beim 74. Rennen bricht er erschöpft zusammen und stirbt.
python3 cat.py
No file given
python3 cat.py nichtda.txt
Traceback (most recent call last):
File "cat.py", line 6, in <module>
with open(sys.argv[1], 'r') as f:
FileNotFoundError: [Errno 2] No such file or directory: 'nichtda.txt'
Übung
Schreiben Sie das Skript so um, dass es den Fehlerfall von nicht vorhanden Dateien auch abfängt.
Lösung
import sys from os.path import exists if len(sys.argv) < 2: print("No file given") else: if exists(sys.argv[1]): with open(sys.argv[1], 'r') as f: print(f.read()) else: print("Datei existiert nicht!")python3 cat.py nichtda.txtDatei existiert nicht!
Kernpunkte
Listen von Strings können mit
nltk.Text()zu einem NLTK-Text umgewandelt werden.Kommandozeilenargumente können über die Liste
sys.argvabgerufen werden. Das erste Element ist immer der Aufrufpfad des Skripts.
POS-Tagger trainieren
Overview
Teaching: 0 min
Exercises: 0 minQuestions
Wie kann ein POS-Tagger in NLTK trainiert werden?
Objectives
Schritte des Lernverfahrens verstehen
RIDGES Korpus
Bitte laden Sie die Datei ridges8_gold.txt aus dem Moodle-Kurs herunter.
Dieses ist ein Subset aus dem RIDGES Korpus mit manuell korrigierten POS-Tags im STTS Tagset
Die Datei besteht aus Sätzen, wobei jeder Satz in einer Zeile geschrieben ist.
Tokens sind durch Leerzeichen abgetrennt und das POS-Tag ist mit / an jedes Token angeängt:
Die/ART Römer/NN nennen/VVFIN es/PPER Pers[('Politik', 'NN'), ('ist', 'VAFIN'), ('ein', 'ART'), ('schweres', 'ADJA'), ('Feld', 'NN'), ('.', '$.')]a/FM ./$.
Dieses Dateiformat kann direkt von NLTK durch den TaggedCorpusReader eingelesen werden.
RIDGES ist ein frei verfügbares Korpus bestehend aus deutsprachige Kräuterkundetexte aus historischen Sprachstufen. Wir wollen auf diesem Goldstandard einen Hidden-Markov-basierten POS-Tagger trainieren.
Dazu müssen wir erst einmal ein paar Module aus NLTK importieren.
import nltk
import nltk.corpus.reader.tagged as tagged
import nltk.tag.hmm as hmm
Dann laden wir die Datei mit dem TaggedCorpusReader. Es gibt noch weitere Korpusreader, die andere Formate verstehen.
Das erste Argument ist das Arbeitsverzeichnis, das zweite eine Liste von Dateien.
gold_corpus = tagged.TaggedCorpusReader(".", ["ridges8_gold.txt"])
Mit der Methode tagged_words() kann man sich eine Liste aller Token und deren Tags ausgeben (als Tupel) lassen.
for w in gold_corpus.tagged_words():
print(w)
Die Methode tagged_sents() liefert eine Liste von Sätzen zurück.
Dabei ist jeder Satz wieder selbst eine Liste von Wörtern.
print(gold_corpus.tagged_sents()[5])
Nun legen wir ein neues HMM Trainings-Objekt mit Standard-Parametern an und trainieren es auf den getagged Sätzen.
trainer = hmm.HiddenMarkovModelTrainer()
model = trainer.train(gold_corpus.tagged_sents())
Die train() Funktion liefert ein Modell aus Objekt zurück. Dieses können wir jetzt nutzen, um eigene Sätze zu taggen.
print(model.tag(nltk.word_tokenize("Majoran ist frisch")))
print(model.tag(nltk.word_tokenize("Majoran ist cool")))
[('Majoran', 'NN'), ('ist', 'VAFIN'), ('frisch', 'ADJD')]
[('Majoran', 'NN'), ('ist', 'VAFIN'), ('cool', 'NN')]
Modelle können mit der Dill-Bibliothek in Dateien gespeichert und wieder geladen werden.
Diese muss erst mit pip in einer Konsole mit aktivierter Conda-Umgebung installiert werden.
pip install dill
Dann kann man ein Modell folgendermaßen speichern:
import dill
dill.dump( model, open( "ridges.model", "wb" ) )
new_model = dill.load( open( "ridges.model", "rb" ))
new_model.tag(nltk.word_tokenize("Die Römer nennen es Majoran"))
[('Die', 'ART'), ('Römer', 'NN'), ('nennen', 'VVFIN'), ('es', 'PPER'), ('Majoran', 'NN')]
Tiger2 Korpus
Das Tiger2-Korpus basiert auf Zeitungstexten und wurde ebenfalls mit dem STTS annotiert. Laden Sie das Korpus “TIGER Corpus Release 2.2” in dem CONLL09-Format von der Tiger2-Webseite herunter: https://www.ims.uni-stuttgart.de/forschung/ressourcen/korpora/tiger/
Das CONLL-Format enthält Informationen über Dependenz-Strukturen, die wir im Moment nicht benötigen.
Es kann aber analog zur Textdatei in NLTK mit dem nltk.corpus.ConllCorpusReader eingelesen werden, dabei muss mit angegeben werden welche Spalten als word oder pos genutzt und welche ignoriert werden sollen.
tiger_corpus = nltk.corpus.ConllCorpusReader('.', 'tiger_release_aug07.corrected.16012013.conll09',
['ignore', 'words', 'ignore', 'ignore', 'pos'],
encoding='utf-8')
Nun kann wieder analog zum RIDGESS Korpus mit den annotierten Daten trainiert und getagged werden. Das Trainieren kann etwas dauern, da Tiger2 deutlich größer ist als der Ausschnitt aus dem RIDGES Korpus.
tiger_model = trainer.train(tiger_corpus.tagged_sents())
tiger_model.tag(nltk.word_tokenize("Politik ist ein schweres Feld."))
[('Politik', 'NN'), ('ist', 'VAFIN'), ('ein', 'ART'), ('schweres', 'ADJA'), ('Feld', 'NN'), ('.', '$.')]
Kernpunkte
Mit dem
HiddenMarkovModelTraineraus demnltk.tag.hmmModul können eigene HMM-basierte POS-Tagger trainiert werdenMit der
dill-Bibliothek können diese Modelle gespeichert und wieder geladen werden.
Textklassifzierung mit Tensorflow
Overview
Teaching: 0 min
Exercises: 0 minQuestions
Wie kann man mit Hilfe von neuronalen Netzen Texte klassifizieren?
Objectives
Tensorflow-API mit Python ansprechen
Daten für Tensorflow aus CSV Dateien einlesen und aufbereiten
Einführung
Textklassifizierung kann für verschiedene Bereiche eingesetzt werden, um Texte Kategorien zuzuweisen. Beispiele dafür sind
- die Kategorisierung von E-Mails in Spam oder Nicht-Spam,
- eine Zuordnung eines Textes zu einem Autor oder Eigenschaften des Autors,
- Positives oder negative Haltung bestimmen (zum Beispiel bei einer Produkt-Bewertung),
- die Sprache eines Textes zu identifizieren.
Bag-Of-Words
Textklassifikation hat den gesamten Text als Eingabe und die Klasse als Ausgabe.
Neuronale Netzwerke haben aber Vektoren von Zahlen als Ein- und Ausgabe.
Um die Ausgabe zu kodieren, kann man Vektoren nutzen, die die gleiche Länge wie die Anzahl der Klassen haben.
Jeder Klasse wird dann ein Index des Ausgabe-Vektors zugeordnet.
Nach Berechnung der Ausgabe des neuronalen Netzwerk ist dann die Klasse, die dem Index mit dem höchsten Wert im Vektor zugeordnet ist die erkannte Klasse.
Wenn man zum Beispiel zwischen den Sprachen „Englisch“, „Deutsch“, „Französisch“ unterscheiden möchte, hat man 3 Klassen und damit Vektor der Länge drei.
Wenn wir also zum Beispiel die Ausgabe (0.13, 0.99, 0.4) haben und Englisch dem ersten Index, Deutsch dem zweiten und Französisch dem dritten Index zugeordnet ist, dann wurde vom neuronalen Netz die Klasse „Deutsch“ vorhergesagt.
Im Fall, dass man nur zwei Klassen hat (z. B. negativ und positiv) kann man auch nur einen einzelnen Wert aus Ausgabe nehmen, der dann 0 für die erste Klasse und 1 für die zweite Klasse ist.
Für die Eingabe, also den eigentlichen Text, müssen wir aber auch eine geeignete Vektordarstellung finden. Dazu nutzen wir in diesem Tutorial sogenannte Bag-Of-Words. Diese Darstellung reduziert den Text auf die Anzahl der genutzten Wörter aus einem vorher festgelegten Vokabular. Für jedes Wort aus dem Vokabular wir die Häufigkeit des Vorkommens bestimmt. Der Kontext oder die Position des Worts im Text geht dabei verloren.
Der Beispieltext
By the time the film ended, I not only disliked it, I despised it.
würde sich folgende Darstellung ergeben:
| word | # |
|---|---|
| by | 1 |
| the | 2 |
| time | 1 |
| film | 1 |
| ended | 1 |
| , | 2 |
| i | 2 |
| not | 1 |
| only | 1 |
| disliked | 1 |
| it | 2 |
| despised | 1 |
| . | 1 |
Klassifzierung nach Sentiment
In diesem Tutorial wollen wir Texte nach ihrer Haltung (Sentiment) klassifizieren.
Dieses Beispiel ist adaptiert von https://realpython.com/python-keras-text-classification/.
Als Daten nutzen wir Kommentare aus der Internet Movie Database1.
Bitte laden Sie den „Data Folder“ von der Homepage des Datasets herunter: https://archive.ics.uci.edu/ml/datasets/Sentiment+Labelled+Sentences und entpacken Sie die Datei sentiment labelled sentences.zip.
Wir verwenden im Tutorial die Datei imdb_labelled.txt.
In dieser Datei sind zeilenweise IMDB-Kommentare mit der Annotation versehen, ob diese negativ (0) oder positiv (1) sind.
Der Kommentar
A very, very, very slow-moving, aimless movie about a distressed, drifting young man.
wurde dabei manuell mit dem Ausgabewert 0 markiert (ist also negativ) während z. B. folgender Kommentar den Wert 1 für positiv bekommen hat:
The best scene in the movie was when Gerardo is trying to find a song that keeps running through his head.
Unsere Aufgabe ist es nun, diese beiden Klassen automatisch mit einem neuronalen Netz auf ungesehener Eingabe zu unterscheiden. Wir wollen also auf den Goldstandard-Daten der IMDB-Kommentare das Netzwerk trainieren und auf neuen Daten anwenden können. Dafür sind mehrere Schritte, von der Aufbereitung der Daten bis zur Definition der Netzwerkstruktur, dem eigentlichen Trainieren und Code zum Ausführen des trainierten Netzwerks notwendig.
Tensorflow (mit Keras API)
Für dieses Beispiel nutzen wir Tensorflow mit der Keras API. Tensorflow kann über pip installiert werden.
pip install tensorflow
Einlesen der CSV Dateien
Der erste Schritt ist das Einlesen der Trainingsdaten.
Die Datei imdb_labelled.txt ist eine CSV- bzw. TSV-Datei: jede Zeile ist ein Datenpunkt und die Informationen in den Zeilen sind durch Tabs separiert (TSV steht für „Tab separated values“, „CSV“ dementsprechend für „Comma separated values“, wird aber oft als Oberbegriff für alle solche Formate unabhängig vom Trennzeichen verwendet).
Wir definieren dazu die Funktion read_csv, die das Einlesen übernimmt und eine Liste von Sätzen/Kommentaren und eine Liste der Kategorien (also die „labels“) zurückgibt.
Diese Funktion (und alle anderen Hilfsfunktionen) werden im Modul util definiert, müssen also in einer Datei mit dem Namen util.py gespeichert werden.
# Liest eine CSV-Datei mit Sätzen und Labeln (0 negativ, 1 positiv) ein
def read_csv(file):
sentences = []
labels = []
with open(file, "r") as f:
# Jede Zeile der Datei einlesen
for line in f.readlines():
# Zeile in zwei Teile spalten (durch Tab getrennt)
splitted = line.split('\t')
# Den Satzteil und das Score jeweils an die entsprechende Liste anhängen
sentences.append(splitted[0])
# Das Label muss zu einer Zahl konvertiert werden
labels.append(float(splitted[1]))
# Beide Listen zurückgeben
return (sentences, labels)
Erstellen eines Vokabulars
Für die Bag-Of-Words-Repräsentation benötigen wir ein Vokabular. Dazu implementieren wir folgene Funkion, die ein Vokabular der 999 häufigsten Wörter aus einer gegebenen Liste von Sätzen berechnet.
# Erstellt eine Zuordnung von den 999 häufigsten Wörtern zu einer ID
def create_vocabulary(sentences):
# Erstelle eine Listen mit allen Wörtern
# Ein Wort kann mehrfach vorkommen, ist aber immer klein geschrieben
all_words = list()
for s in sentences:
for token in nltk.tokenize.word_tokenize(s):
all_words.append(token.lower())
# Erstelle eine Frequenzliste aller Wörter
fdist = nltk.FreqDist(all_words)
# Erstelle eine Zuordnung von den 999 häufigsten Wörtern zu einer ID
vocabulary = dict()
# Die ID 0 wird freigelassen für unbekannte Wörter
ident = 1
for word, _ in fdist.most_common(999):
vocabulary[word] = ident
ident = ident + 1
return vocabulary
Erstellen eines Bag-Of-Words für jeden Satz
Als nächsten Schritt definieren eine Funktion, die die eigentlichen Bag-Of-Words für alle Sätze gegeben des Vokabular berechnet. Da das Vokabular nicht vollständig ist, werden alle unbekannten Wörter mit der speziellen ID 0 kodiert.
# Erstellt eine Liste von Bag-Of-Words-Vektoren für eine Liste von Sätzen.
def create_bag_of_words(sentences, vocabulary):
result = []
for s in sentences:
# Erstelle Liste mit nullen
# Die Liste ist so lang wie es Einträge im Vokuabular gibt (plus 1 für die 0)
# Jedes Listenelement entspricht der Anzahl der Token für die ID an dieser Position
v = [0]*(len(vocabulary)+1)
for token in nltk.tokenize.word_tokenize(s):
token = token.lower()
# Unbekannte Wörter bekommen die ID 0
identifier = 0
if token in vocabulary:
# Schlage die ID für bekannte Wörter im Vokabular nach
identifier = vocabulary[token]
# Erhöhe die Anzahl der Wörter mit dieser ID um 1
v[identifier] = v[identifier] + 1
# Hänge den Bag-Of-Word Vektor für diesen Satz an das Ergebnis an
result.append(v)
# Gebe die Bag-Of-Word Vektoren als Liste zurück
return result
Aufbereitung der Daten
Um beurteilen zu können, wie gut das neuronale Netz gelernt hat, trennen wir die Daten in eine Trainingsdatenmenge und eine Testdatenmenge auf. Die Performanz (also Anzahl korrekter Vorhersagen) wird dann auf den ungesehenen Testdaten berechnet.
Aus den Trainingsdaten berechnen wir das Vokabular: die Testdaten dürfen nicht ins Vokabular eingehen, da diese ja ungesehene neue Daten repräsentieren. Für beiden Datenmengen wird mit dem Vokabular für jeden Satz eine Bag-Of-Words Vektorrepräsentation erstellt.
import util
import dill
# CSV Datei einlesen
sentences, y = util.read_csv("imdb_labelled.txt")
# Aufspalten in Training und Testmengen
# 75% der Daten zum Training, 25% zum Testen
split_position = int(len(sentences) * 0.75)
# Trainingsdaten
sentences_train = sentences[:split_position]
y_train = y[:split_position]
# Testdaten
sentences_test = sentences[split_position:]
y_test = y[split_position:]
# Erstelle Vokabular aus den Traningsdaten
# und transformiere alle Sätze in Bag-Of-Words Vektoren
vocabulary = util.create_vocabulary(sentences_train)
x_train = util.create_bag_of_words(sentences_train, vocabulary)
x_test = util.create_bag_of_words(sentences_test, vocabulary)
Trainieren eines neuronalen Netzes
Wir kommen jetzt zum eigentlichen Training. Dazu definieren wir ein Netzwerk mit der folgenden Struktur:

Der Eingabe-Layer hat 1000 Neuronen, da unser Vokabular 999 Wörter plus das ungesehene Wort umfasst.
Jedes Neuron im Eingabe-Layer bekommt die Anzahl des ihm zugeordneten Worts als Eingabe.
Danach wird ein einfacher Hidden-Layer mit 10 Neuronen geschaltet.
Die Ausgabe hat nur ein Neuron, das entweder den Wert 0 für negativ oder 1 für positiv annehmen soll.
Das folgende Skript nutzt nun die Tensorflow-API um dieses Netzwerk zu definieren und die passenden Gewichte für die bereits erstellten Trainingsdaten zu lernen. Tensorflow überprüft für die verschiedenen Iterationen der Gewichtsanpassungen mit Hilfe der Testdaten, wie gut das Netz bereits gelernt hat. Die trainierten Modelldaten (inklusive Vokabular) werden gespeichert
from tensorflow.keras.models import Sequential
from tensorflow.keras import layers
# Definiere ein Neuronales Netz mit einem Bag-Of-Words Vektor als Eingabe
# einem Hidden Layer und einer Ausgabe
model = Sequential()
model.add(layers.Dense(10, input_dim=len(x_train[0]), activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
# Muss einmal "kompiliert" werden
model.compile(loss='mse', optimizer='adam', metrics=['accuracy'])
print(model.summary())
# "fit" trainiert das Modell auf den gegebenen Daten
model.fit(x_train, y_train, epochs=20, validation_data=(x_test, y_test), batch_size=10)
model.save("classifier.h5")
# Auch das Vokabular abspeichern, sonst können wir keine neuen Vektoren erstellen
dill.dump(vocabulary, open("vocabulary.dat", "wb"))
Ausgabe für ein paar Testdaten
Mit den gespeicherten Modelldaten können wir nun in einem neuen Skript eigene Eingaben ausprobieren.
import util
import dill
from tensorflow.keras.models import load_model
# Vokabular und Modell des neuronalen Netzes laden
vocabulary = dill.load(open("vocabulary.dat", "rb"))
model = load_model("classifier.h5")
# Beispieleingaben erzeugen
example_sentences = ["This movie is worse than anything else.",
"Best movie ever!",
"You can not imagine a better movie!",
"I would love to see this again. Bruce Wayne is great.",
"YAML SDFA FAFAFCA FAF AFAF"]
x = util.create_bag_of_words(example_sentences, vocabulary)
# Ausgabe vorhersagen
y = model.predict(x)
for i in range(0, len(y)):
print(example_sentences[i], y[i])
This movie is worse than anything else. [0.10687903]
Best movie ever! [0.7610351]
You can not imagine a better movie! [0.09572864]
I would love to see this again. Bruce Wayne is great. [0.9571661]
YAML SDFA FAFAFCA FAF AFAF [0.5089223]
-
Kotzias, Dimitrios, Misha Denil, Nando De Freitas, and Padhraic Smyth. 2015. “From Group to Individual Labels Using Deep Features.” In Proceedings of the 21th Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, 597–606. ACM. ↩
Kernpunkte
Die Keras-API von Tensorflow erlaubt es relativ einfach neuronale Netze zu definieren, trainieren und anzuwenden
Datenaufbereitung und Umwandlung von Texten in Vektoren fester Länge macht einen großen Teil der Arbeit aus
Kollaboratives Arbeiten mit Git
Overview
Teaching: 0 min
Exercises: 0 minQuestions
Wie kann man gemeinsam Software entwickeln?
Welche Möglichkeiten gibt es den Quelltext zu teilen?
Objectives
Einfache Git-Kommandos ausführen
Projekte in GitLab anlegen und Dateien synchronisieren
Einführung und Terminologie
Das Arbeiten an Quelltexten ist typischerweise inkrementell. Das führt schnell dazu, dass man Überblick über die verschiedenen Versionen verliert. Beim Schreiben von Texten gibt es dann oft die Strategie, die Versionierung im Dateinamen auszudrücken (also z.B. “final.doc”, “final_rev2.doc”, final_final.doc”).1 Außerdem benötigen wir bei gemeinsamen Arbeiten in Projekten auch einen gemeinsamen Stand des Quelltexts, auf den alle Projektmitglieder zugreifen können.
Anstatt manuell eigene Versionierungs-Mechanismen zu erarbeiten, können wir auch bestehende Versionskontrollsysteme (VCS) nutzen. Dieses soll uns in die Lage versetzen
- Änderungen unabhängig vom Dokument betrachten,
- Änderungen in Dokumenten automatisch zu verfolgen,
- Änderungen rückgängig zu machen bzw. „zurückspulen“,
- nachvollziehen zu können, wer in dem Projekte welche Änderungen gemacht hat,
- nicht aus Versehen Änderungen anderer übersehen und/oder überschreiben.
Inzwischen hat sich das Kommandozeilen-Programm Git als de-facto Standard Versionskontrollsystem für Quelltexte etabliert. Man kann es aber auch für andere Textdatei-lastige Projekte, wie zum Beispiel Korpusannotationsdateien nutzen.
Die Konzepte von Versionsverwaltungsprogrammen folgen einer eigenen Terminologie, die gerade am Anfang etwas überwältigend sein kann. Im Glossar der GitHub-Platform können Sie die wichtigsten Begriffe, die wir auch hier verwenden werden, nachschlagen. Dazu gehören unter anderem,
- repository https://help.github.com/en/github/getting-started-with-github/github-glossary#repository
- clone https://help.github.com/articles/github-glossary/#clone
- fetch https://help.github.com/articles/github-glossary/#fetch
- pull https://help.github.com/articles/github-glossary/#pull
- commit https://help.github.com/articles/github-glossary/#commit
Tools und Plattformen
Um gemeinsam Quelltexte zu bearbeiten, benötigen wir zwei Dinge:
- die Software zum Versionieren selbst (in diesem Fall Git)
- einen Ort an dem wir von Git erstellten Repositories abspeichern und von dem wir unsere eigenen Kopien synchronisieren.
Wir werden die grafische Oberfläche GitHub Desktop (nicht zu verwechseln mit der Online-Platform GitHub.com, aber von der gleichen Firma) nutzen, die Sie von https://desktop.github.com/ für Ihr Betriebsystem herunterladen können.
Für Linux werden inoffizielle Installationspakete unter https://github.com/shiftkey/desktop/releases/ bereitgestellt.
Gleichzeitig werden wir auch immer für jede Aktion in GitHub Desktop den entsprechenden Git-Kommandozeilen-Aufruf zeigen.
GitHub Desktop bringt seine eigene Git-Installation mit.
Um die Kommandozeilenbefehle nachzuvollziehen, müssen Sie Git für die Kommandozeile von https://git-scm.com/downloads installieren. Unter Linux ist git typischerweise schon in den Paketquellen vorhanden und kann zum Beispiel mit sudo apt install git unter Ubuntu installiert werden.
Eine populäre Platform für Git-basierte Projekte ist GitHub.com, die zum Konzern Microsoft gehört. Diese erlaubt inzwischen auch das Erstellen von nicht-öffentlichen Projekten und kann daher auch für eigene Studien-Projekte geeignet sein. Daneben gibt es aber auch Alternativen wie GitLab, das einerseits eine zentrale Plattform analog zu GitHub.com ist, deren Software man aber auch auf eigenen Servern installieren und betreiben kann. Die HU-Berlin betreibt unter https://scm.cms.hu-berlin.de/ eine solche GitLab-Instanz auf ihren eigenen Servern, auf der Sie sich mit Ihrem CMS-Acccount einloggen können. Diese verschiedenen Plattformen haben oft ähnliche Funkionen, wie zum Beispiel Ticketsysteme zum Verwalten von Bugs und TODOs. In diesem Tutorial werden wir die GitLab-Instanz der HU nutzen, aber das Prinzip ist für die anderen Plattformen gleich.
Anlegen eines neuen lokalen Git-Repositories
Git arbeitet auf sogenannten Repositories, die alle Dateien und die komplette Versionshistorie beinhalten.
Ein Git-Repository besteht aus einem lokalen Ordner mit den zu versionierenden Dateien und einem speziellen versteckten Unterordner .git.
Zum Anlegen eines Git-Reppositories, starten Sie GitHub Desktop. Beim ersten Start wird das Programm Sie auffordern, einen Account auf GitHub.com anzulegen, da wir das GitLab der HU nutzen werden, können Sie diesen Schritt bedenkenlos überspringen.
Trotzdem benötigt Git die Angabe eines Namens und einer E-Mail-Adresse. Diese Informationen werden in der Versionshistorie als Felder für den Autor angezeigt. Beide Angaben werden nur lokal gespeichert und nicht verifiziert, weder der Name noch die E-Mail-Adresse müssen stimmen.
Wählen Sie im Startbildschirm von GitHub Desktop jetzt „Create a new Repository on your hard drive…“ aus, um ein neues Repository als Ordner in einem beliebigen Pfad anzulegen.
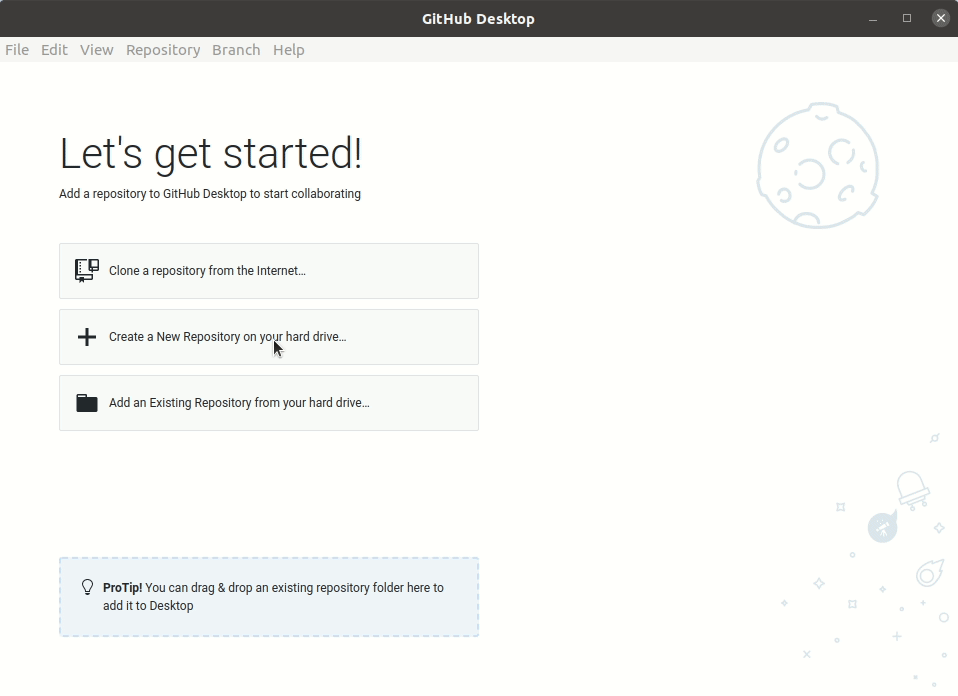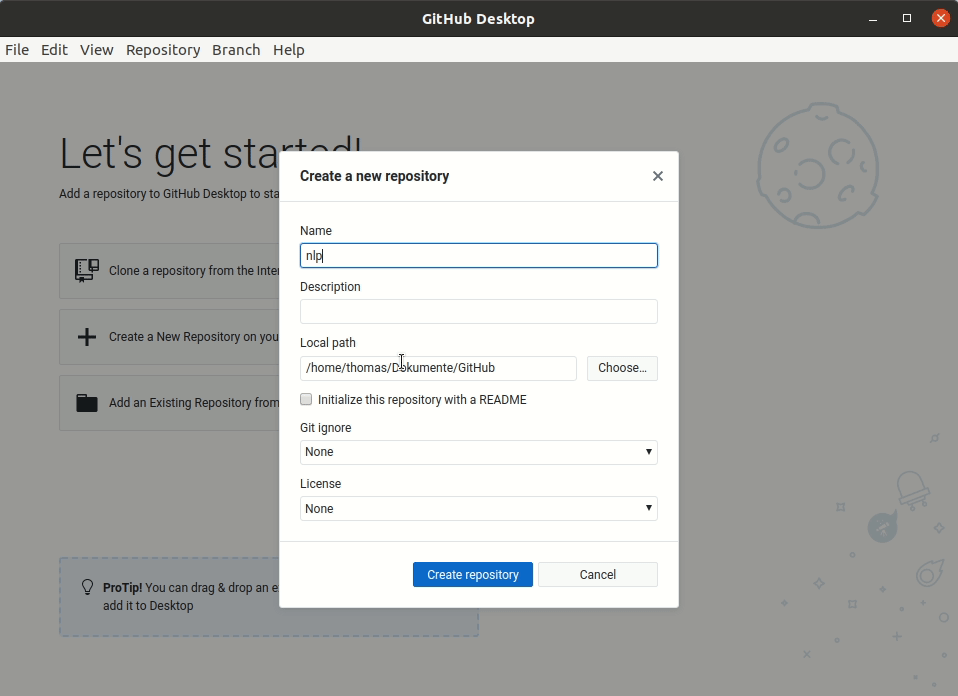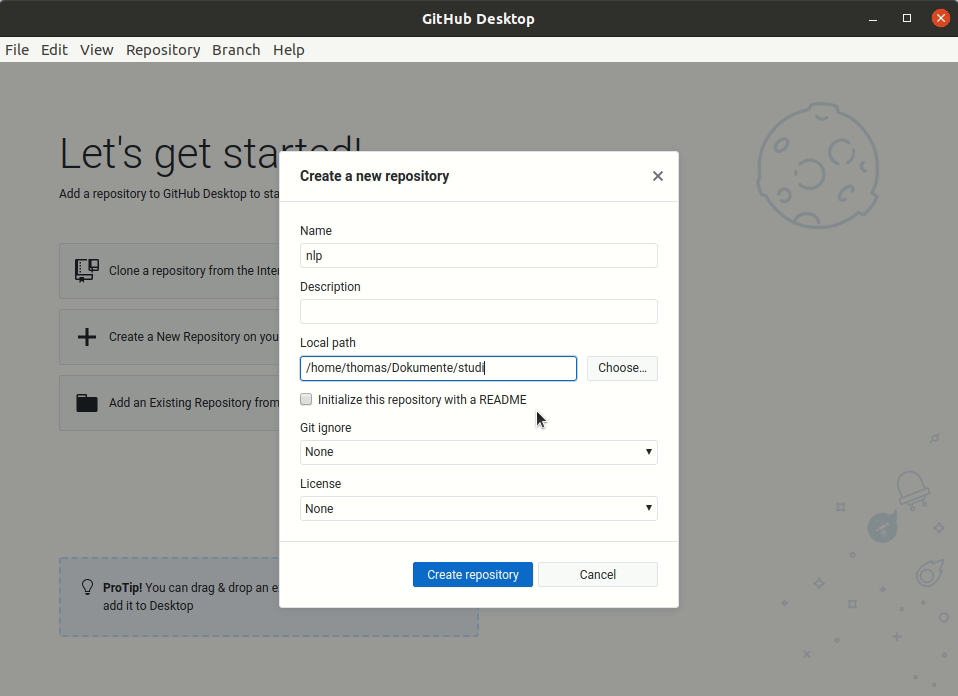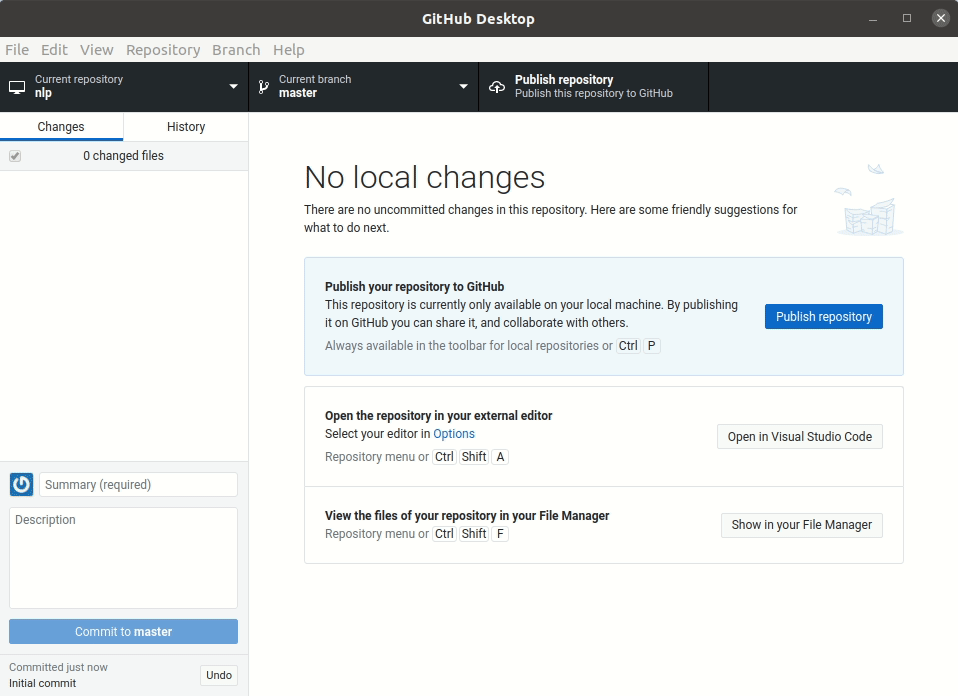
Falls bereits ein Repository offen ist, können Sie neue Repositories auch das Menü und “File -> New repository” anlegen.
Auf der Kommandozeile würde man erst einen neuen Ordner erstellen, in diesem mit cd wechseln und dann git init ausführen, um das gleiche Ergebnis zu erreichen.
mkdir nlp
cd nlp
git init
Leeres Git-Repository in /home/thomas/Dokumente/studium/nlp/.git/ initialisiert
Diesen Ordner, oder Arbeitskopie oder “working tree” genannt, können Sie nun wie einen normalen Ordner im Dateisystem benutzen. Sie können Ihn auch in Visual Studio Code öffnen, um Dateien anzulegen oder zu editieren. GitHub Desktop bietet einem sogar einen Link an, um das Repository direkt zu in Visual Studio Code zu öffnen
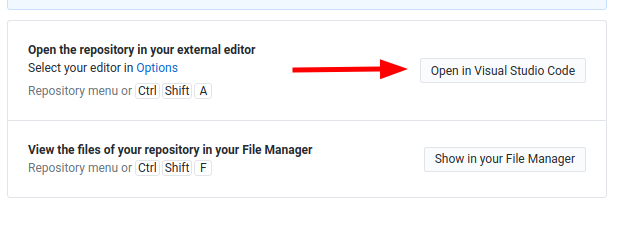
Dateien hinzufügen und ändern
Legen Sie jetzt eine neue Python-Datei mit dem Namen main.py im Repository, zum Beispiel über Visual Studio Code an.
name = input("Wie heißen Sie: ")
print("Hallo " + name)
Im Gegensatz zu Programmen wie Dropbox oder der HU Box müssen Änderungen an den Dateien explizit markiert und in einem Commit zusammengefasst werden. In GitHub Desktop markiert man dazu die geänderten Dateien, füllt eine Commit-Nachricht aus und comitted die Änderungen. Dieser Commit ist dann Teil der History des Repositories. Wenn alle lokal geänderten bzw. hinzugefügten Dateien Teil des Commits waren, wird GitHub Desktop “No local changes” anzeigen.
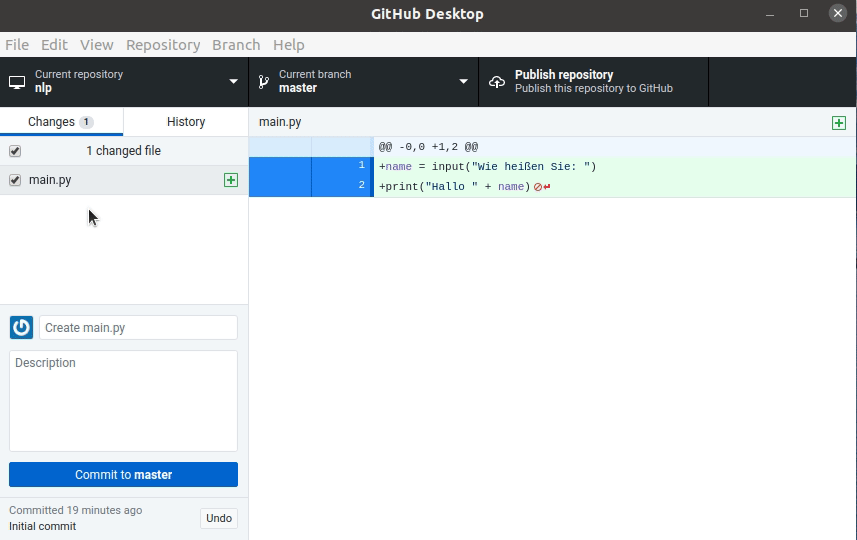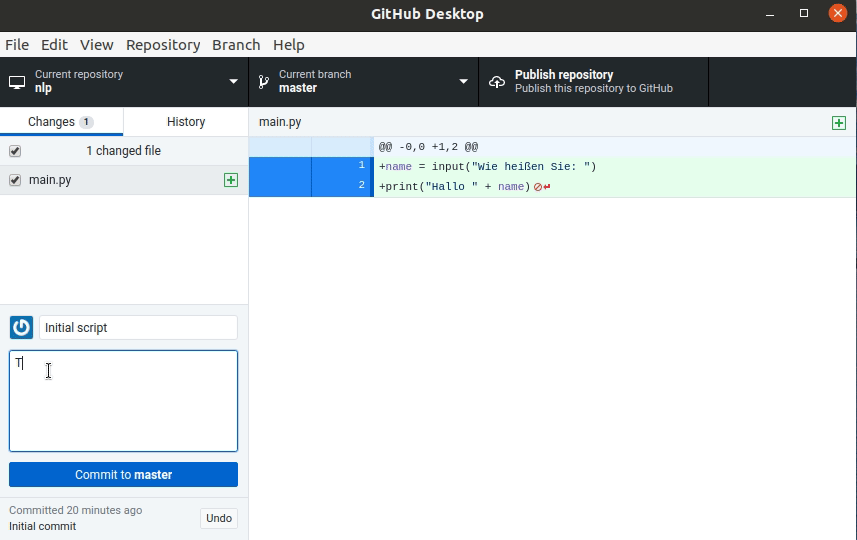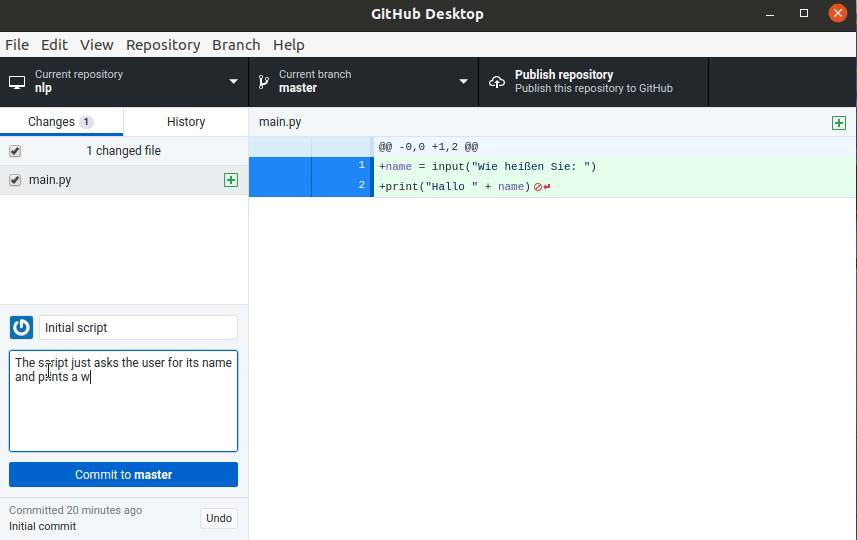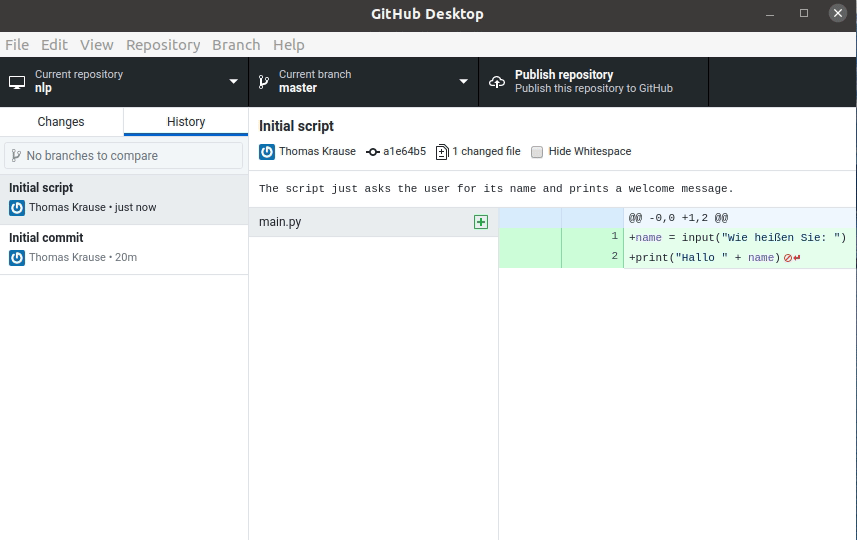
Auf der Kommandozeile werden Änderungen mit git add <datei> vorgemerkt und dann mit git commit -m Nachricht comitted.
git add main.py
git commit -m "Initial Script"
Git verwaltet Änderungen zeilenweise.
Sobald eine Datei geändert wird, zeigt GitHub Desktop die geänderten Zeilen an.
Ändern Sie main.py so, dass am Ende der Ausgabe ein Ausrufezeichen steht, speichern Sie die Datei ab und GitHub Desktop wird die lokalen Änderungen anzeigen.
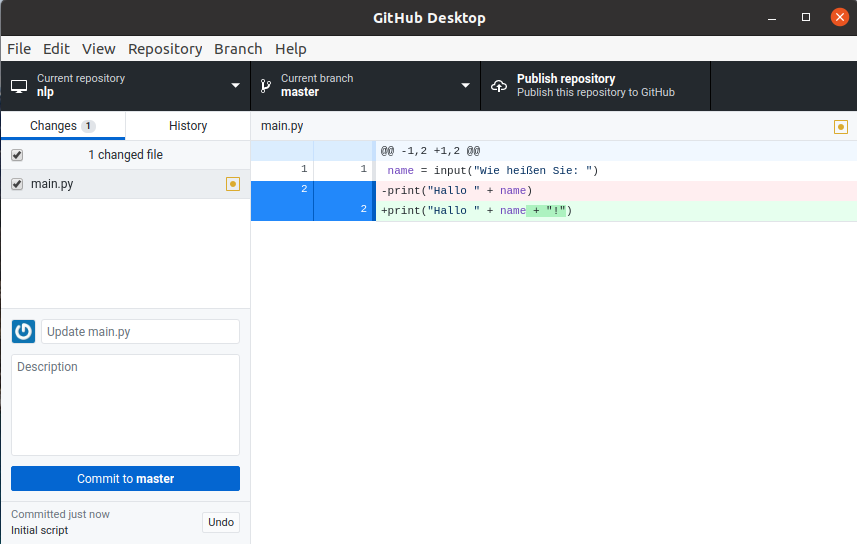
Äquivalent dazu ist der Aufruf von git diff auf der Kommandozeile.
git diff
diff --git a/main.py b/main.py
index f0b5686..936e410 100644
--- a/main.py
+++ b/main.py
@@ -1,2 +1,2 @@
name = input("Wie heißen Sie: ")
-print("Hallo " + name)
+print("Hallo " + name + "!")
Markieren Sie auch die neuen Änderungen und committen Sie diese mit einer Aussagekräftigen Commit-Nachricht, zum Beispiel “Added more excitement when welcoming the user.”. In dem Tab “History” listet GitHub Desktop alle Commits mit ihren Nachrichten, dem Autor und den geänderten Zeilen auf.
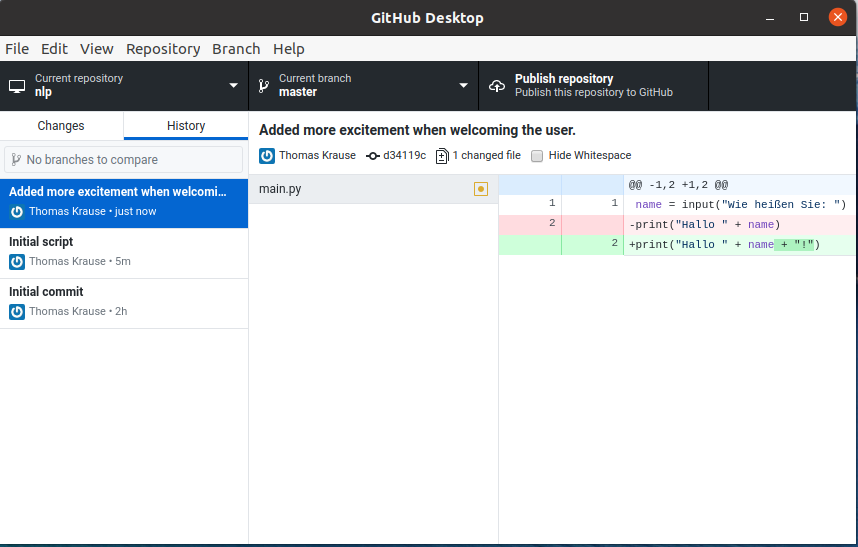
Jeder Commit hat dabei eine eindeutige ID, in dem Screenshot ist es zum Beispiel d34119c für den Commit, in dem das Ausrufezeichen hinzugefügt wurde (unter dem Titel oben rechts im Bild).
Diese ID wird bei Ihnen anders sein, da der Nutzername, die E-Mail, Zeitstempel und alle bisherigen Commits in die Berechnung dieser ID eingehen.
Wenn zwei Commit die gleiche ID haben können Sie sich sicher sein, dass Sie die gleiche Version des Repositories mit dem gleichen Dateiinhalt haben.
Auf der Kommandozeile listet git log alle Commits und ihre ID auf.
git log
commit d34119cd81d054d02b87dedd6dbff14ef65e93b8 (HEAD -> master)
Author: Thomas Krause <krauseto@hu-berlin.de>
Date: Tue Jun 9 16:54:04 2020 +0200
Added more excitement when welcoming the user.
commit f22fe3b7787a10c18039e907474d0cef03785705
Author: Thomas Krause <krauseto@hu-berlin.de>
Date: Tue Jun 9 16:49:00 2020 +0200
Initial script
The script just asks the user for its name and prints a welcome message.
commit 561e8c6b06e757868fd31bafa619e7c0b43c01e8
Author: Thomas Krause <krauseto@hu-berlin.de>
Date: Tue Jun 9 14:36:46 2020 +0200
Initial commit
Im Gegensatz zu GitHub Desktop listet git log die komplette ID und nicht nur die ersten Zeichen auf.
Zur eindeutigen Identifikation des Commits reichen aber meist die ersten 7 Zeichen.
Sie können lokale Änderungen auch rückgängig machen anstatt Sie zu committed.
Wenn Sie zum Beispiel das Ausrufezeichen in ein Fragezeichen ändern und main.py speichern, wird die Änderungen in GitHub Desktop angezeigt.
Sie können dann mit der rechten Maustaste auf die geänderte Datei unter “Changes” klicken und “Discard changes…” auswählen.
Dieser Befehl ändert die Datei auf der Festplatte, weswegen ein extra Bestätigungsdialog erscheint.
Die Kommanzeilenvariante basiert auf dem Befehl git checkout <version> <file>, der Dateien in bestimmten Versionen aus dem Repository wiederherstellt.
Wir verwenden die spezielle Meta-Version “HEAD”, die für den letzten lokalen Commit steht.
git checkout HEAD main.py
1 Pfad von 80b993b aktualisiert
Synchronisieren von Repositories
Anlegen eines neuen Projekts in GitLab
Um Quelltexte zu teilen, muss man ein Repository auf einem Server anlegen. Für das GitLab der HU loggen Sie sich zuerst unter https://scm.cms.hu-berlin.de/ ein und drücken Sie dann die grüne “New Project” Schaltfläche.
Füllen Sie danach das Eingabeformular für neue Projekte mit dem Namen und einer optionalen Beschreibung aus. Sie können einstellen, wer das Projekt sehen kann. Stellen Sie sicher, dass “Initialize repository with a README” nicht ausgewählt ist.
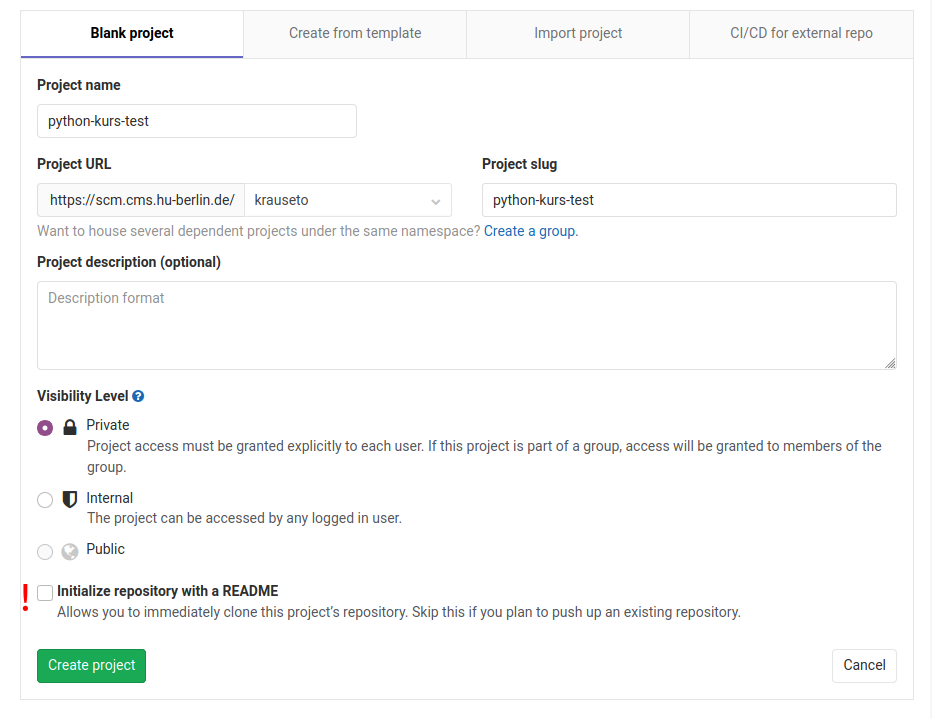
Pushen der Änderungen
Das erstelle Repository ist komplett leer, beinhaltet also keine Commits. Um die lokalen Commits zum entfernten Repository hinzuzufügen, muss es als sogenanntes Remote-Repository registriert werden. Dazu klicken Sie zuerst auf die blaue “Clone” Schaltfläche und kopieren Sie die URL unter “Clone with HTTPS”.
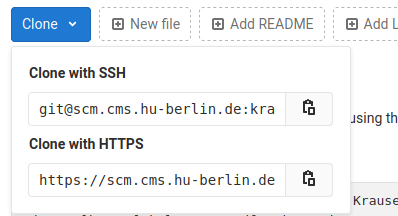
Das Registrieren des Remote-Repositories geht leider nicht im GitHub Desktop Client2, deswegen müssen wir auf die Kommandozeile ausweichen und im Repository-Ordner als aktuellem Verzeichnis folgenden Befehl ausführen:
git remote add origin https://scm.cms.hu-berlin.de/krauseto/python-kurs-test.git
Dieser Befehl fügt ein neues Remote-Repository mit dem Namen “origin” und gegebenen URL hinzu (diese muss natürlich ihre eigene URL, nicht die aus dem Beispiel sein).
Sie müssen das Remote-Repository nur einmal hinzufügen. Danach können Sie auch weiter in GitHub Desktop arbeiten. Der erste Schritt ist, alle lokalen Commits in das entfernte Repository mit “Publish changes” zu übertragen.
Ein Neuladen der Projekt-Seite in GitLab sollte nun die Dateien des Repositories anzeigen.
Auf der Kommandozeilen kann man alle lokalen Commits mit
git push origin master
“origin” ist der vorher vergebene Kurzname für das Remote-Repository und “master” der sogenannte Branch, der übertragen werden soll. Wir werden später Branches kennenlernen, im Moment müssen Sie aber nur wissen, dass der Standard-Branch “master” heißt.
Hinzufügen andere Entwickler
Auf ein Remote-Repository können mehrere Nutzer zugreifen. Fügen Sie Ihre Projektmitglieder unter “Settings -> Members” hinzu. Um mit am Quelltext arbeiten zu können, muss mindestens die Rolle “Developer” zugewiesen werden.
Klonen eines neuen Repositories
Im Projekt werden Sie vermutlich nur ein Repository nutzen.
Einer der Team-Mitglieder erstellt dieses Repository und die anderen müssen es dann auf Ihren Rechner übertragen.
Auf der Kommandozeile würde man dazu ein neues Verzeichnis erstellen und mit git clone und der URL, die man über die Schaltfläche “Clone” erhalten hat ein neues lokales Repository als Kopie erstellen.
Als weiteres optionales Argument kann man den Namen der neuen Arbeitskopie (also des Ordners) angeben.
cd ~/Dokumente/studium/
git clone https://scm.cms.hu-berlin.de/krauseto/python-kurs-test.git nlp-clone
cd nlp-clone
Über das Menü “File -> Clone repository” kann man im GitHub Desktop ebenfalls ein bestehendes Projekt klonen. In der Projektübersicht links oben kann man dann zwischen den verschiedenen Arbeitskopien die in GitHub Desktop registriert sind wechseln.
Änderungen vom Remote-Repository übernehmen
Wenn andere Entwickler Änderungen comitten und per “push” übertragen, können wir zwar die Änderungen in der GitLab Projektansicht sehen, aber haben den neuesten Stand der Dateien nicht lokal in unserem eigenen Repository. Das Holen der Änderungen vom entfernten Repository ist in Git eine explizite Aktion. Um zu emulieren, dass ein anderes Mitglied committed und dann gepushed hat, klicken wir in der Projektansicht von GitLab auf die Datei “main.py” und editieren sie direkt in GitLab.
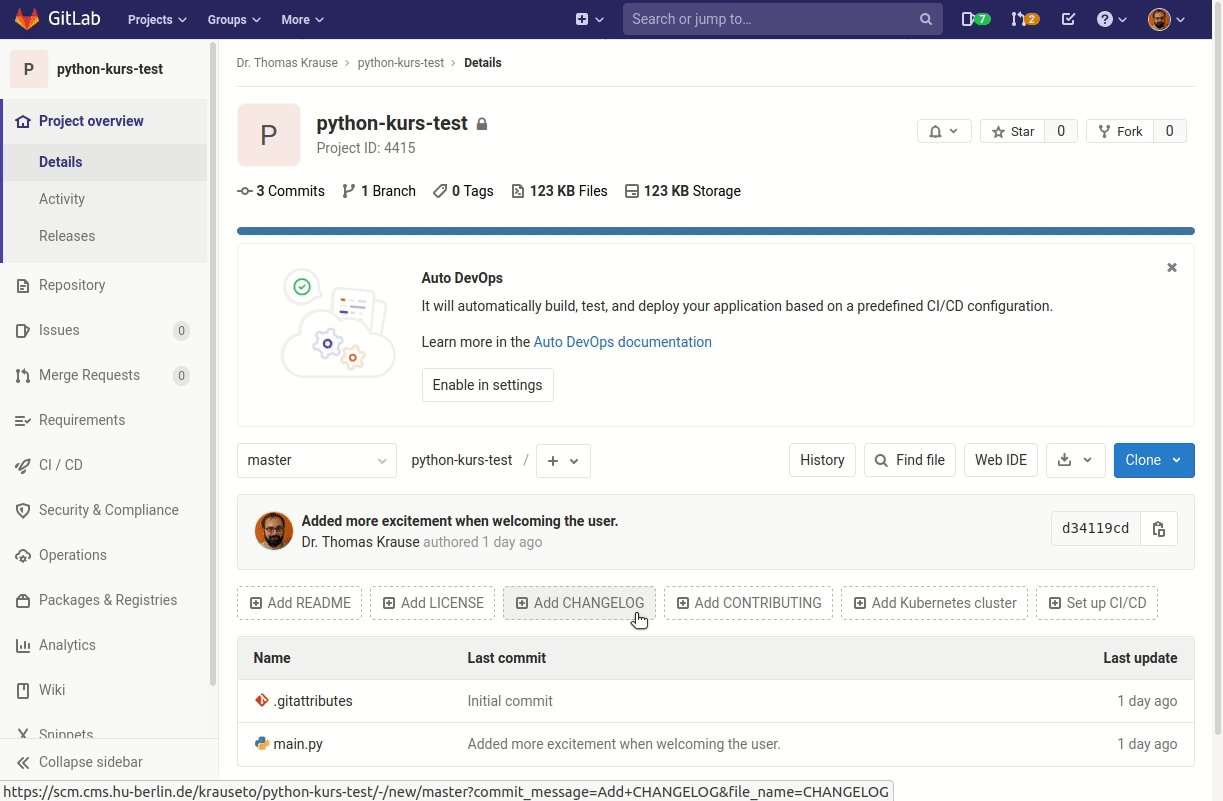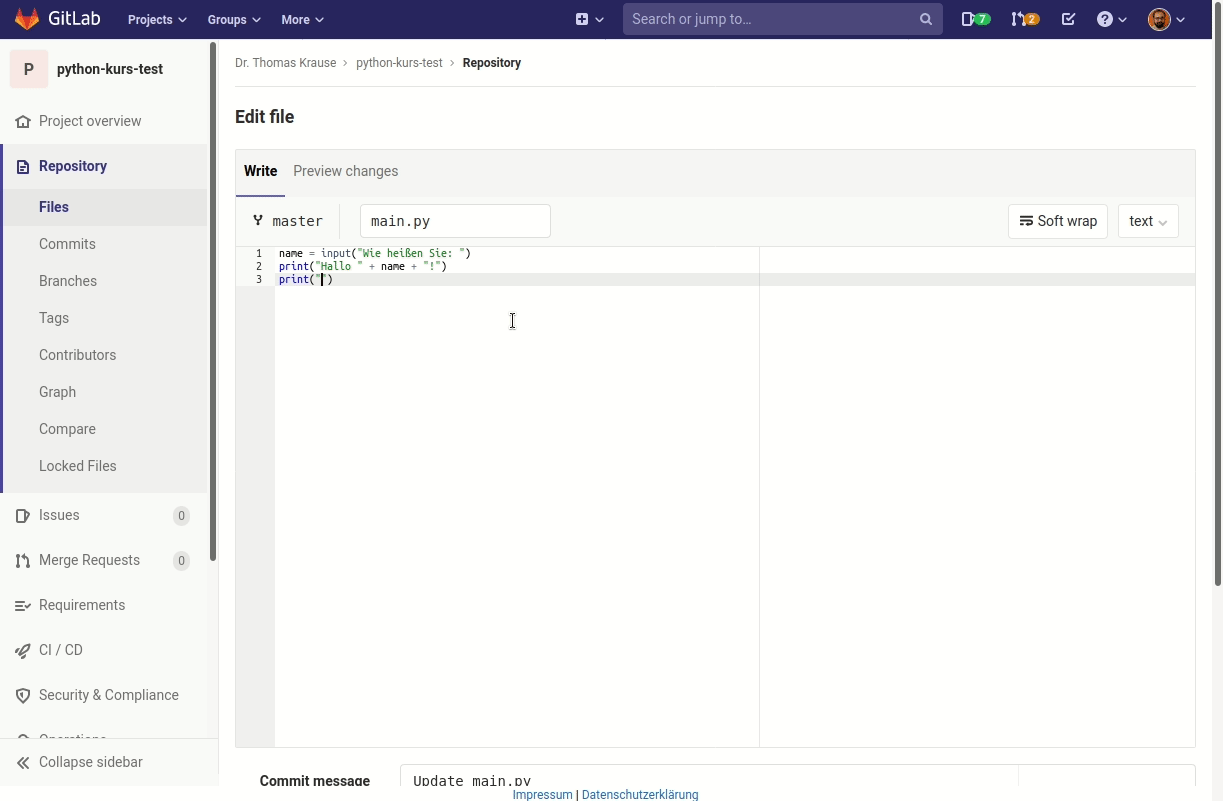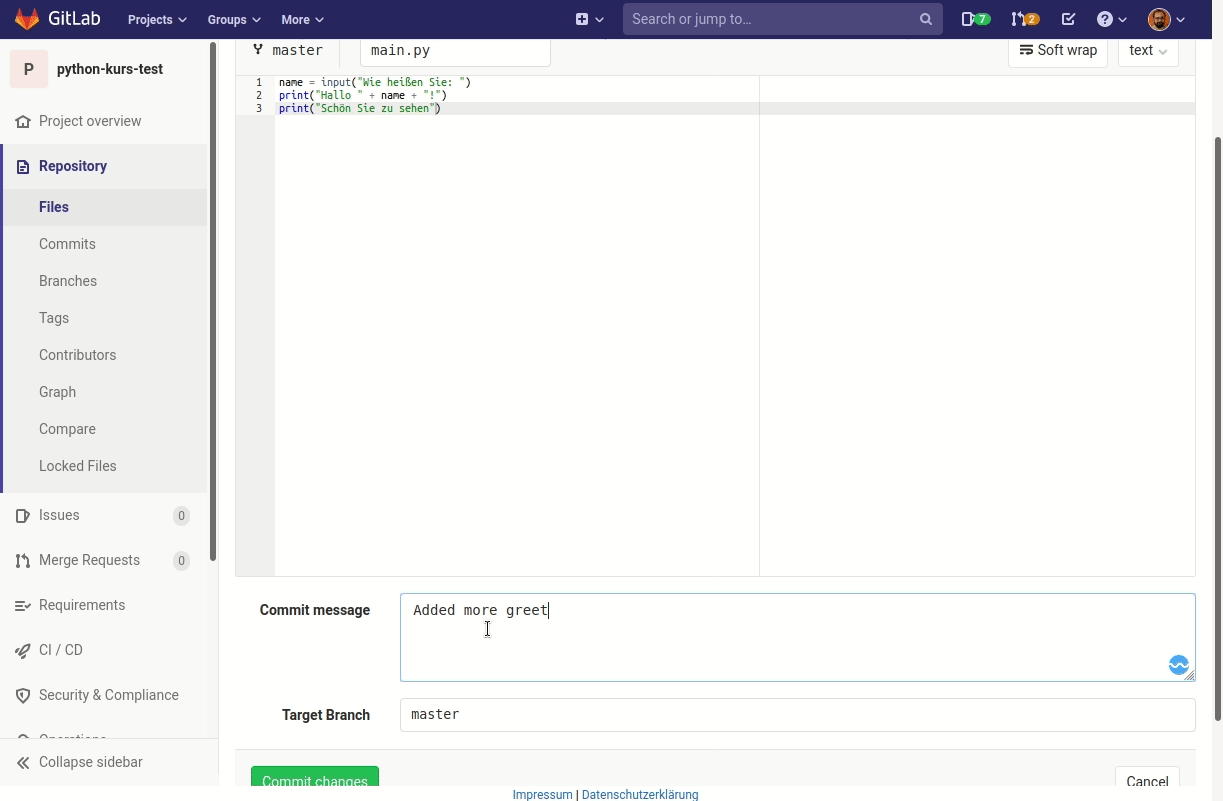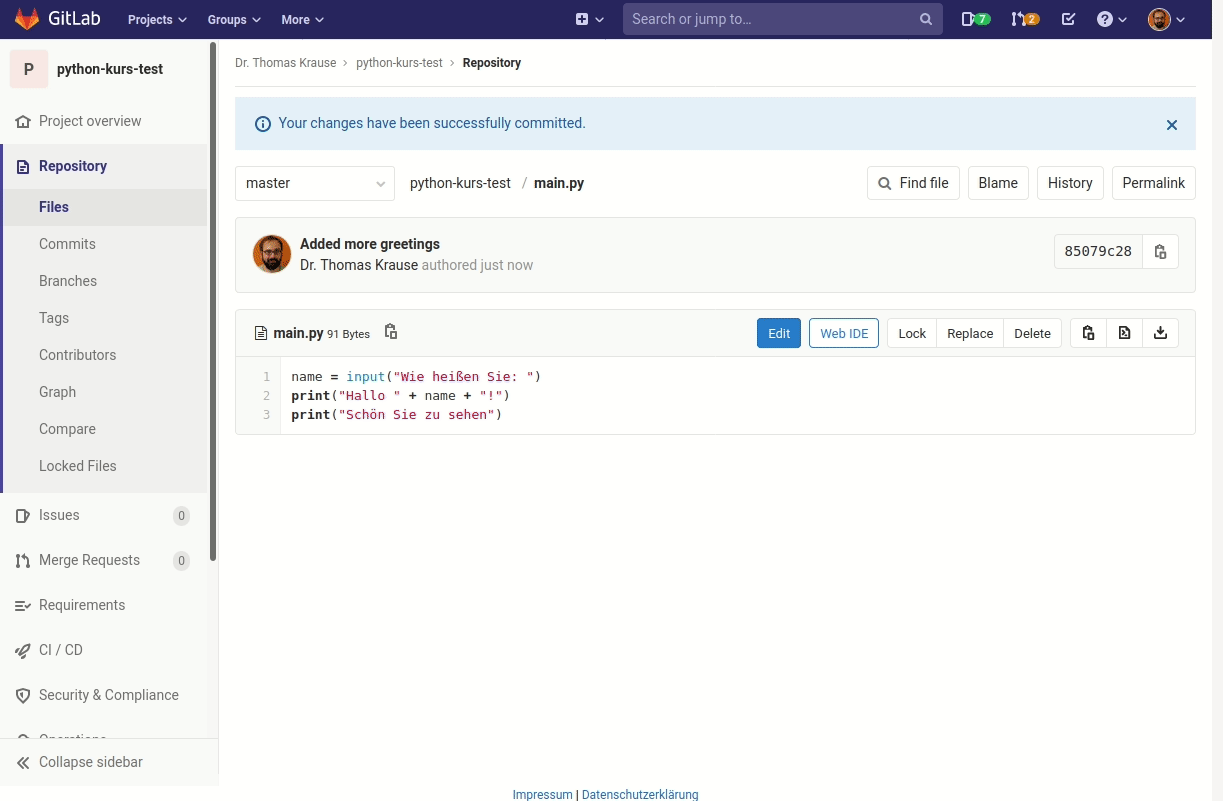
Diese entfernten Änderungen können Sie dann in GitHub Desktop erst “fetchen” und dann “pullen”.
Der Schritt “Fetch origin” überträgt die Commits.
Der Pfeil mit der “1” zeigt an, dass ein entfernten Commit bereitsteht und angewendet werden kann.
Die zweite Aktion “Pull origin with rebase” aktualisiert dann die Dateien im Arbeitsordner auf den aktuelleren Commit des entfernten Repositories anstatt des älteren lokalen Commits.
 Die entsprechenden Kommandozeilenbefehle sind entsprechend:
Die entsprechenden Kommandozeilenbefehle sind entsprechend:
git fetch origin
git pull origin master
Solange das Remote-Repository keine neueren Commits hat, kann man nun neue lokale Commits wieder mit “push” zum Remote-Repository hochladen.
Falls es neuere Commits gibt, kann man diese zuerst “fetchen” und dann “pullen”.
Legen Sie zum Beispiel eine neue Datei README.md mit dem einer Projektbeschreibung in Markdown an.
# Beispiel-Seminarprojekt
TODO: Beschreibung des Vorhabens
## Setup
Installieren Sie alle benötigten Pakete mit:
```
pip install nltk
```
Mit dem “Add”, “Commit, und “Push” können Sie diese Änderungen wieder hochladen. Dieser Zyklus aus Pullen und Pushen wiederholen Sie für jede Änderung.
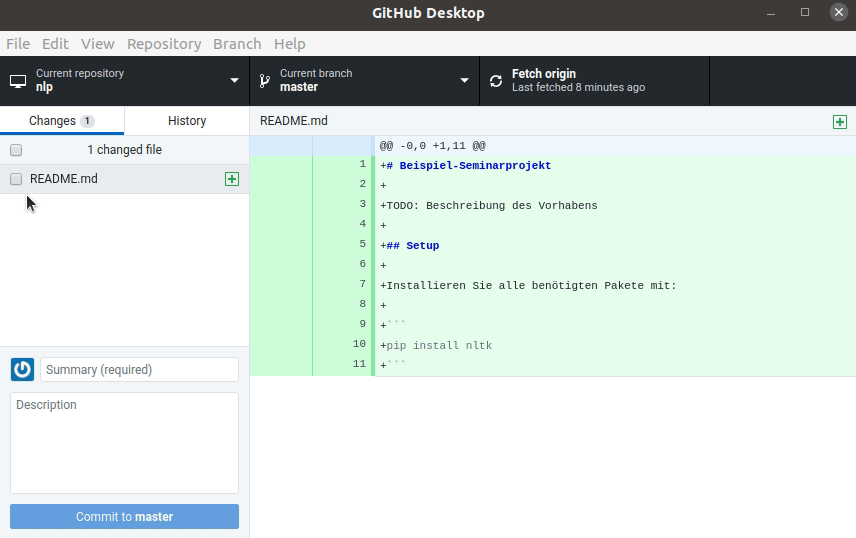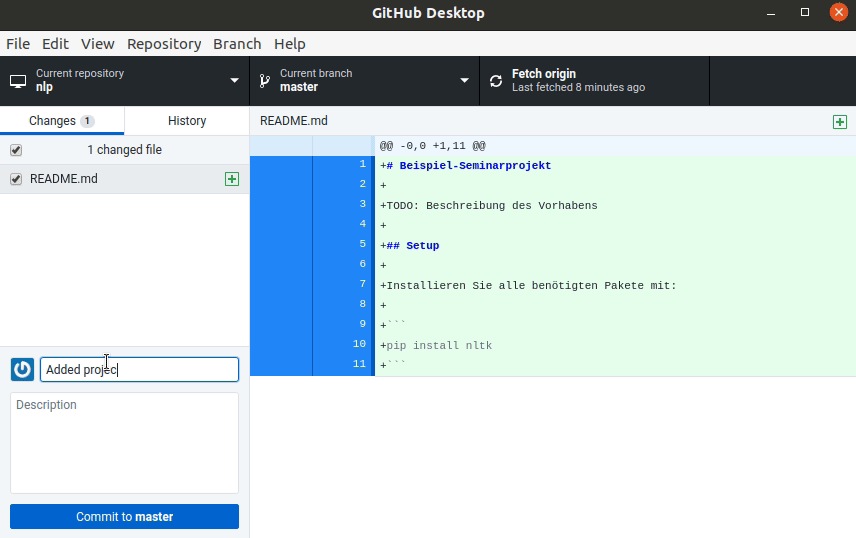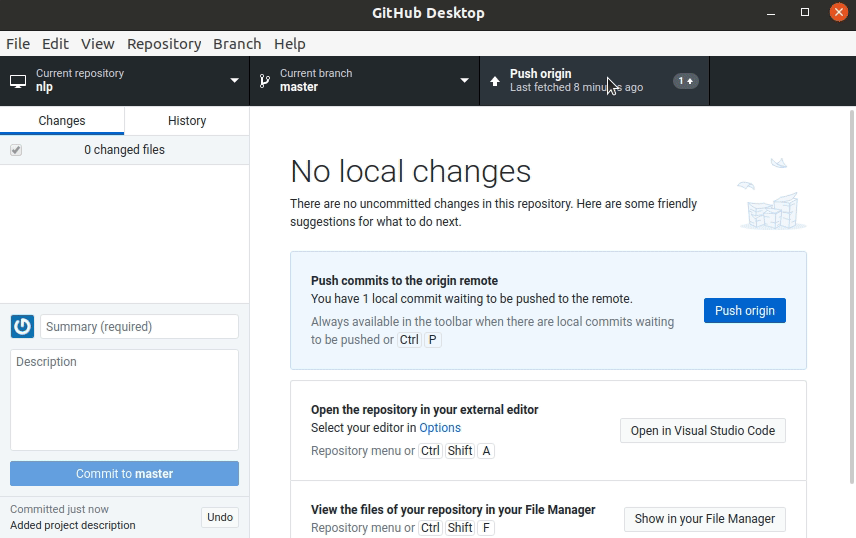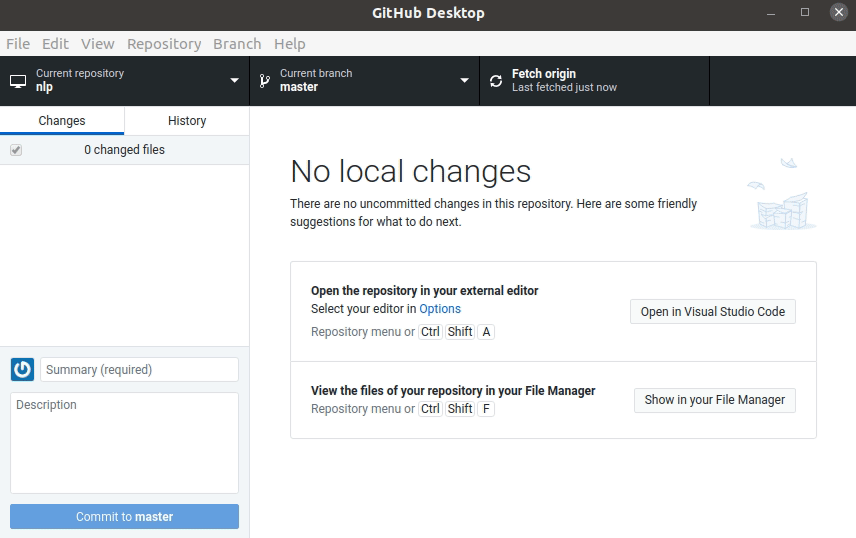
Wann sollte man pullen und pushen?
Pullen und pushen Sie möglichst häufig, damit Ihr lokaler Stand nicht zu sehr von dem der anderen Projektmitglieder abweicht. Bevor Sie zum Beispiel anfangen lokal die Quelltexte zu bearbeiten, sollten Sie vorher einmal “Pull” ausgeführt haben. Committen Sie auch kleine Änderungen und pushen Sie sie gleich nach dem Commit.
Branches
Bisher haben wir nur Änderungen (also Commits) nur linear aufeinander aufgebaut. Auf Commit A folgt Commit B etc. Zum Beispiel würden die Commit-Befehle
git add file1.txt
git commit -m "commit A"
git add file2.txt
git commit -m "commit B"
git add file1.txt
git commit -m "commit C"
zu einer linearen Commit-Historie führen:
master branch
|
+ commit A
|
+ commit B
|
+ commit C
|
...
Ein Branch ist dabei die Sammlung einer linearen Abfolge von Commits.
Git erlaubt das Abzweigen eines neuen Branches von einer bestehenden Commit-Abfolge.
Nach dem Abzeigen mit git branch <Name neuer Branch> muss man die lokale Arbeitskopie auf diesen Branch umstellen git checkout <Name neuer Branch> und kann dann unabhängig vom Original-Branch commiten, bis man die beiden Branches wieder zusammenführt, in dem man zuerst die Arbeitskopie wieder auf den master-Branch mit git checkout master umschalten und dann den neuen Branch merged git merge <Name neuer Branch>. zusammenführt.
master branch
|
|\
| \
| bugfix-123 branch
commit A + |
| |
| + commit B
| + commit C
| /
|/
+ merging branch
“master” enthält nach dem Mergen alle Commits aus beiden Branches.
GitHub Desktop erlaubt ebenfalls das abzweigen und zusammenführen neuer Branches sowie das Umschalten der Arbeitskopie auf den Stand eines jeweiligen Branches.
Auf welchem Branch die Arbeitskopie aktuelle eingestellt ist, wird oben unter “Current Branch” angzeigt. In dem Branch können Sie nun neue Commits hinzufügen. Um Sie zu mergen, wechseln Sie erst zurück auf den “master” branch, klicken Sie dann auf die Branch-Auswahl Schaltfläche und wählen Sie “Choose a branch to merge into master”. Wählen Sie den Branch aus und bestätigen Sie das mergen. Die neuen Commits sollten Sie danach direkt auch wieder pushen.
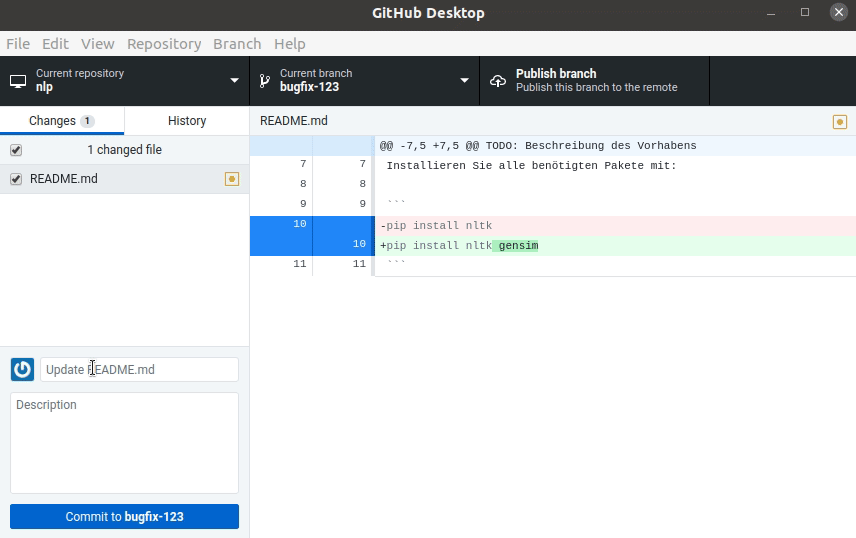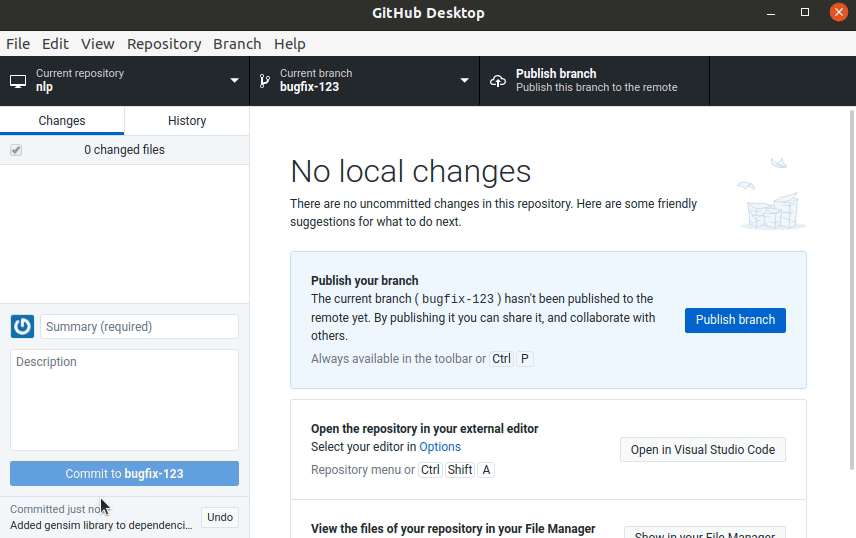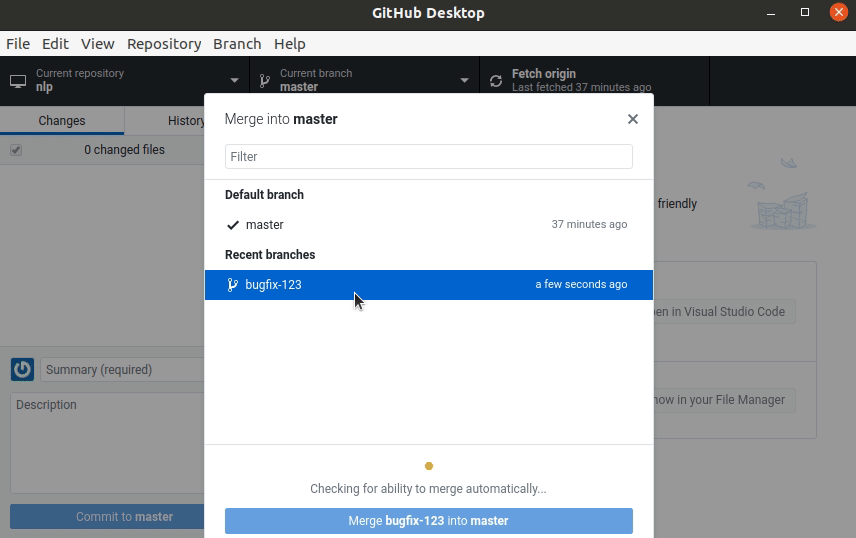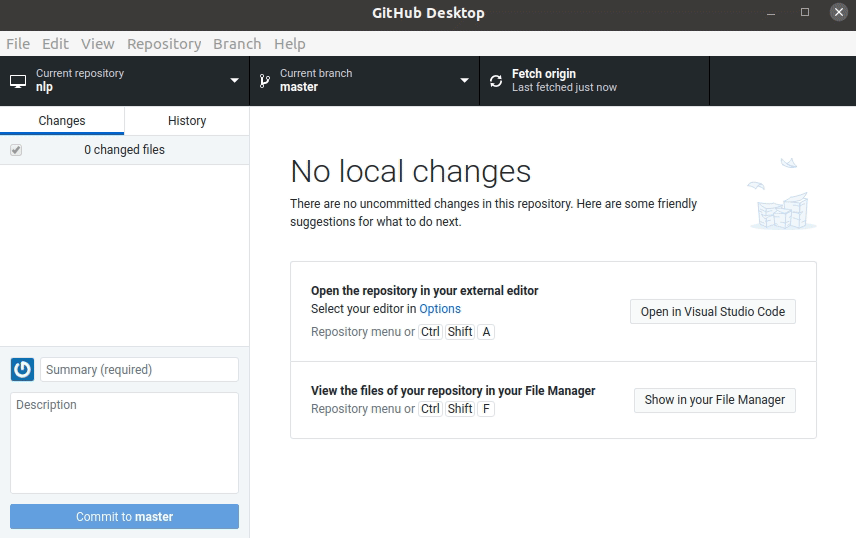
Sie können auch Branches auf dem entfernten Repository mit “Publish” und “Push” hochladen.
Weiterführende Themen
GitHub Desktop Hilfe
Git hat sehr viele Funkionen und gerade der Umgang mit Branches kann am Anfang schwierig sein. Die Online-Hilfe von GitHub Desktop beschreibt viele typische Git-Arbeitsschritte, darunter auch die hier vorgestellten: https://help.github.com/en/desktop/contributing-to-projects.
Konflikte
Besonders wichtig ist der Umgang mit Konflikten. Wenn zwei Entwickler an verschiedenen Dateien oder verschieden Zeilen der gleichen Datei arbeiten, wird Git beim mergen die Versionen einfach zusammenführen. Bei Änderungen an der gleichen Datei in der gleichen Zeile wird es aber zu so einem sogenannten Konflikt kommen. Diesen müssen Sie manuell auflösen (also bestimmen welche Zeile übernommen wird und welche nicht). Neuere Versionen von GitHub Desktop unterstützen Sie bei der Auflösung des Commits. Wenn ein Konflikt ensteht, können Sie entweder auswählen welcher der beiden Versionen (aus Ihrem Branch oder dem entfernten) genommen werden soll oder Sie können die Datei in Visual Studio Code öffnen lassen.
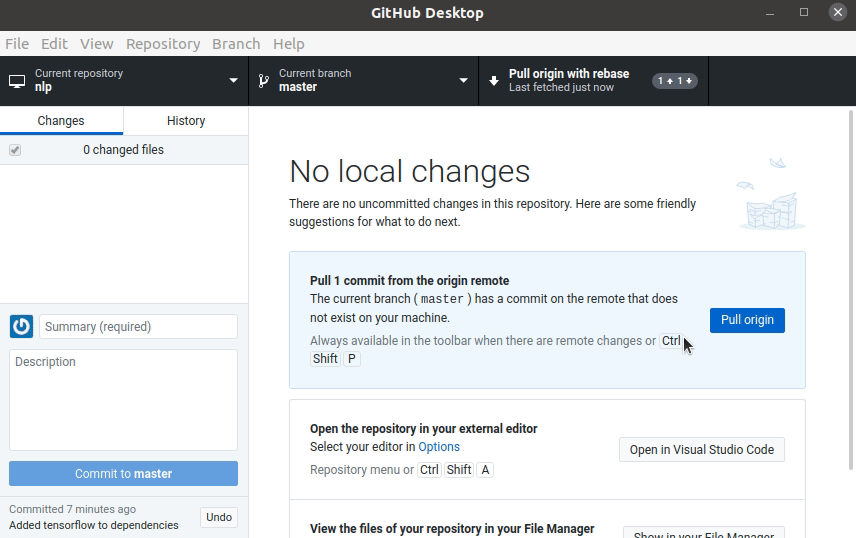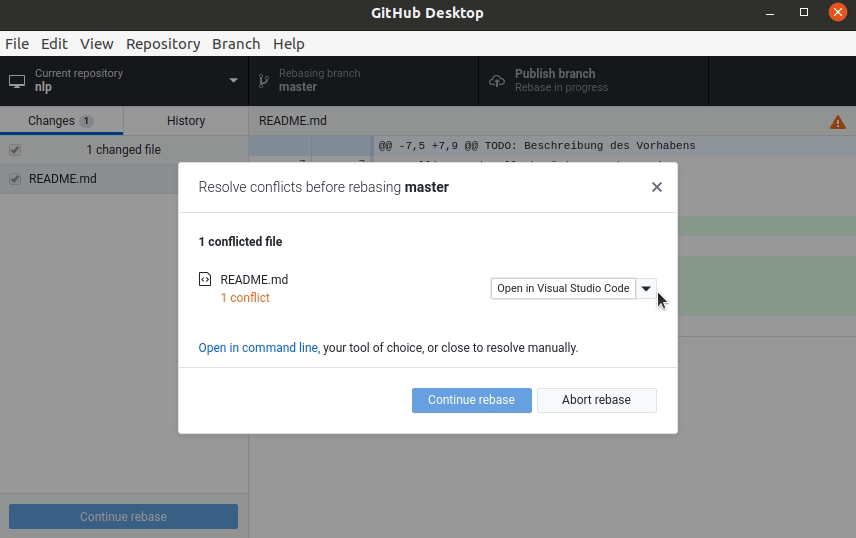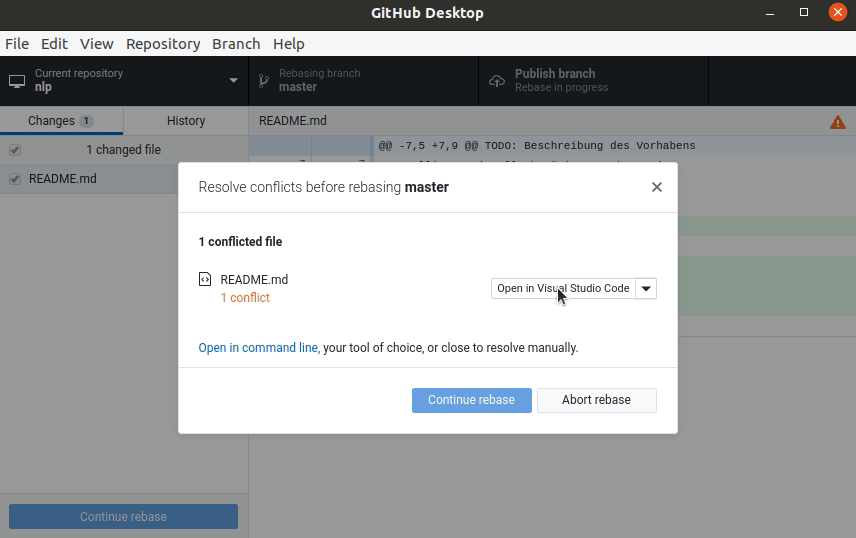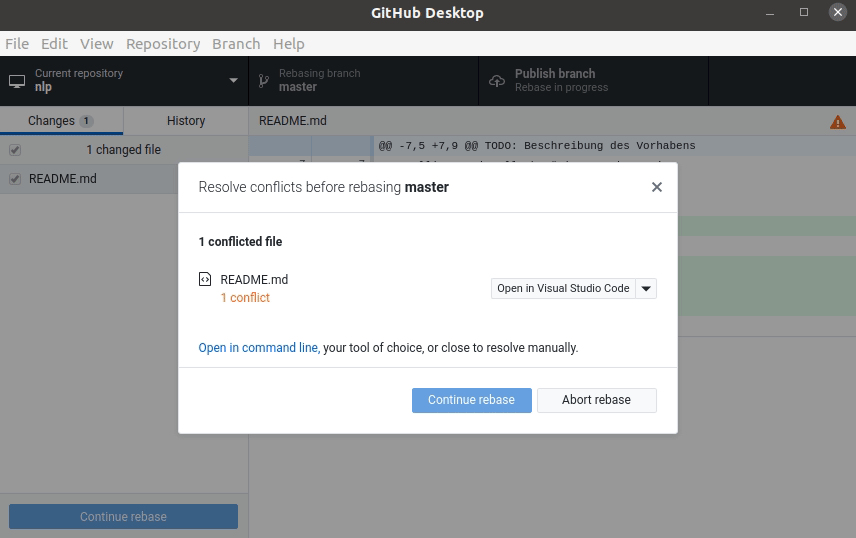
Die Datei mit dem Konflikt enthält beide Zeilen und die Markierungen <<<<<<< am Konflikt-Anfang ======= für die Grenze zwischen der einen und der anderen Variante und “»»»>” für das Ende des Bereichs mit dem Konflikt.
<<<<<<< HEAD
pip install nltk gensim art
=======
pip install nltk gensim tensorflow
>>>>>>> Added tensorflow to dependencies
Passen Sie die Datei manuell mit den gewünschten Änderungen an und stellen Sie sicher, die Zeilen mit den Konflikt-Markern dabei entfernt zu haben. Also zum Beispiel durch die zusammengeführte Zeile, die beide neuen Abhängigkeiten enthält.
pip install nltk gensim art tensorflow
Sobald Sie die Konfliktmarker entfernt haben, wird GitHub Desktop erlauben das Mergen fortzusetzen.
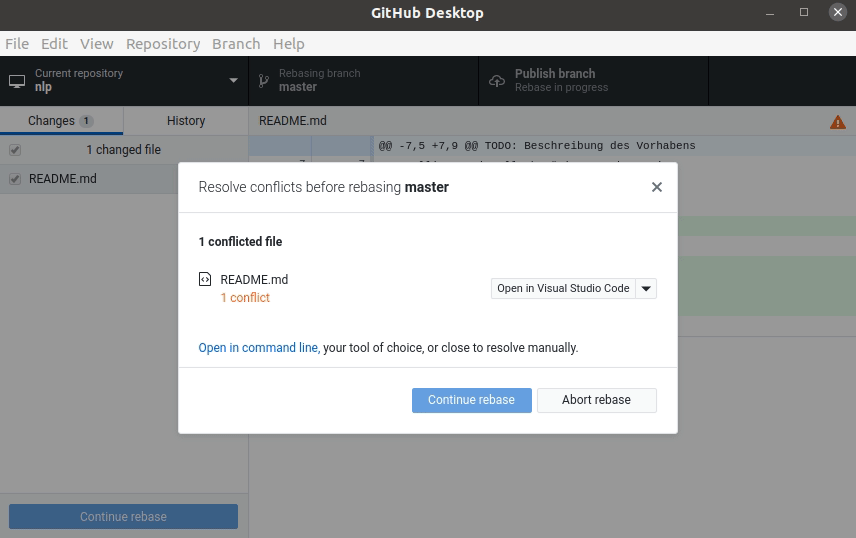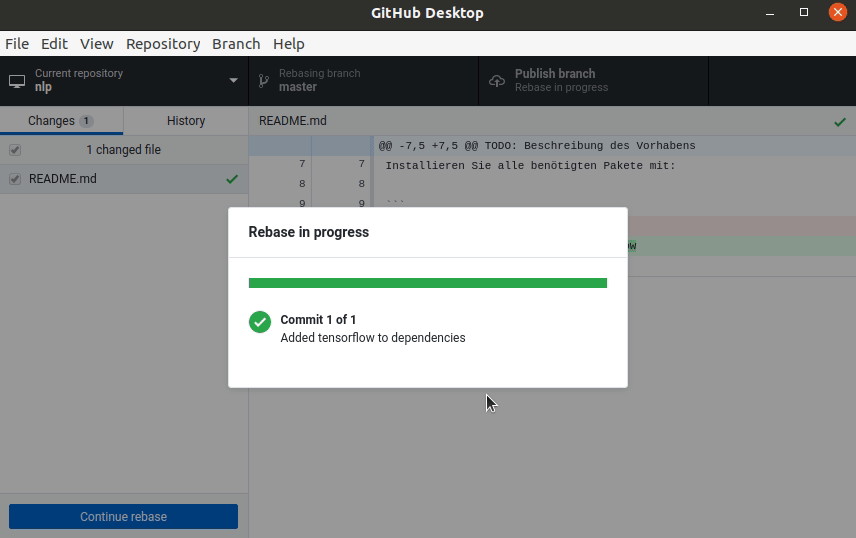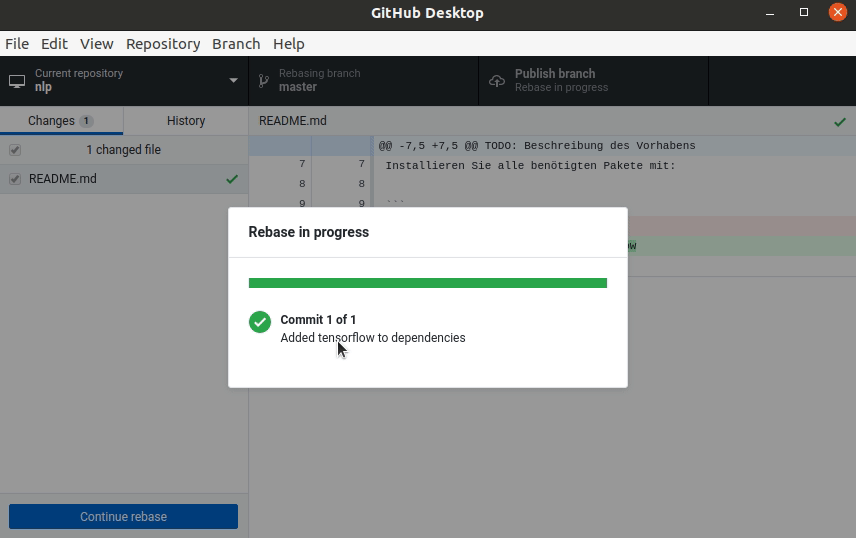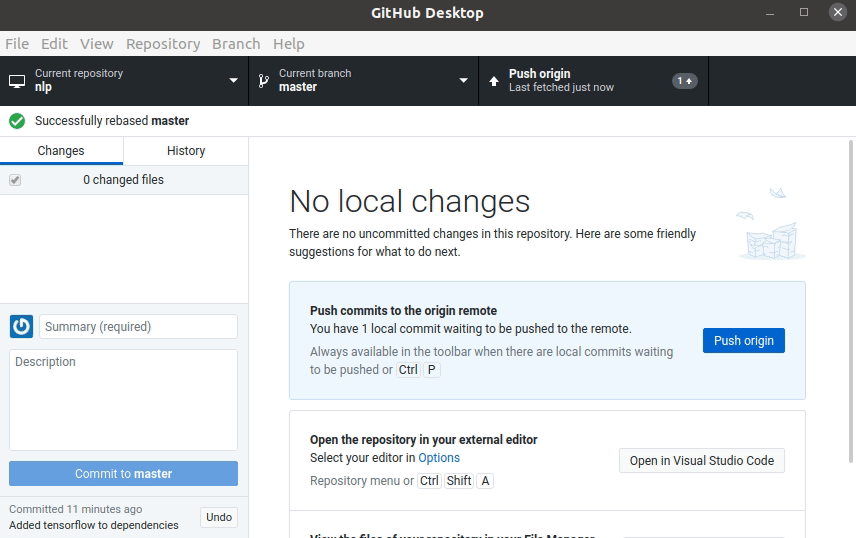
Mehr über Git Kommandozeile
Um sehr tief in die Bedienung von Git auf der Kommandozeile einzusteigen, können Sie die Lektionen zu Git vom Software Carpentry Projekt durcharbeiten: http://swcarpentry.github.io/git-novice/.
-
Zu den Problemen die durch „Versionen“ im Dateinamen entstehen können, sei auch die PHD Comics Episode dazu empfohlen. ↩
-
GitHub möchte mit seinem Produkt natürlich die eigene Plattform unterstützen, deswegen ist es kein Problem unter “Publish Repository” ein GitHub.com Repository auszuwählen, aber leider nicht von anderen Plattformen wie dem HU GitLab. ↩
Kernpunkte
Git ist eine Software zum Verwalten der Quelltexte, um Git herum gibt es Plattformen wie GitLab oder GitHub, die als zentraler Hub für das Projekt dienen
Man kann Git als Kommandozeilenprogramm nutzen, aber auch grafische Oberflächen wie „GitHub Desktop“